V
主页
【bd5m】寻狗的尴尬瞬间
发布人
-
打开封面
下载高清视频
观看高清视频
视频下载器
震撼着看完啦!吴恩达教授《从人类反馈中进行强化学习RLHF, Reinforcement Learning from Human Feedback》(中英字幕)
基于人类反馈的强化学习(Reinforcement Learning From Human Feedback)
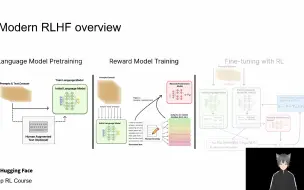
从零实现ChatGPT:从人类反馈中强化学习(RLHF)--HuggingFace
【李宏毅2024春最新】第8讲 生成式AI导论(中文)RLHF 大预言模型修炼史(3) by Hung-yi Lee
清华博后带你走进ChatGPT——ChatGPT与RLHF(3)
RLHF实际上是如何工作的
ChatGPT狂飙:强化学习RLHF与PPO!【ChatGPT】原理第02篇
【入门】大语言模型常用微调框架介绍|LoRA&Prefix-Tuning&Prompt-Tuning&P-Tuning v2&RLHF微调原理简介
RLHF大模型加强学习机制原理介绍
大语言模型RLHF算法PPO讲解
大语言模型LLM第三集:RLHF
【论文必读#9:chatGPT】基于人类反馈的强化学习,一文彻底搞懂原理细节
【王树森】深度强化学习(DRL)
B站首推!李宏毅大佬花一周讲完!2023公认最通俗易懂的【强化学习教程】小白也能信手拈来(人工智能|机器学习|深度学习|强化学习)
全网最通俗易懂,大模型偏好对齐RLHF从PPO推导DPO再推导simPO
吴恩达大模型【Langchain-ChatGLM】已开源!手把手带你实现:大模型预训练和模型微调,我1小时就学会了!
【双语字幕+资料下载】伯克利CS285 | 深度强化学习(2020最新·全23讲)
PPO@RLHF ChatGPT原理解析
不愧是李宏毅老师讲的【强化学习】简直太详细!!!导师不教你的,李宏毅老师亲自教你,这还不赶紧学起来!!!-人工智能/强化算法/机器学习
吴恩达大模型【Langchain-ChatGLM】已开源!手把手带你实现:大模型预训练和模型微调,我1小时就学会了!
SFT和RLHF的区别是什么?
【LibrAI | 智衡 阅读会】第一期:DPO与PPO之争,谁才是RLHF的通解?
大模型成功背后的RLHF到底是什么?
[pytorch 强化学习] 01 认识环境(environment,gym.Env)以及 CartPole-v0/v1 环境
GPT-4论文精读【论文精读·53】
这是B站目前讲的最好的【强化学习实战】教程!带你从零详解PPO算法/DQN算法/A3C算法教程!
吴恩达《大语言模型运维|LLMOps》中英字幕
InstructGPT 论文精读【论文精读·48】
【莫烦Python】强化学习 Reinforcement Learning
Reinforcement Learning 强化学习
【第七期】东大NLP实验室博士完整地剖析RLHF技术方法!
【15集全】2019斯坦福大学最新公开课 Reinforcement Learning Winter
用RLHF的方法解读论语
谷歌周彦祺: 大语言模型扩展——从幂律到稀疏性(GPT大模型训练方法系列【二】)
全栈大模型微调框架LLaMA Factory:从预训练到RLHF的高效实现
快被强化学习劝退了
吴恩达《使用大型语言模型的生成式人工智能》Generative AI with Large Language Models
关于我的强化学习模型不收敛这件事
【强化学习】一小时完全入门
吴恩达《AI高级检索:Chroma|Advanced Retrieval for AI with Chroma》(中英字幕)