V
主页
[DRL] 从策略梯度到 TRPO(Lagrange Duality,拉格朗日对偶性)
发布人
本期 code:https://github.com/chunhuizhang/personal_chatgpt/blob/main/tutorials/drl/policy_based/pg_trpo_ppo.ipynb 重要性采样(IS)On Policy => Off policy:https://www.bilibili.com/video/BV1Vr421u7Qz Policy Gradient(REINFORCE):https://www.bilibili.com/video/BV1eg4y1s7TN/
打开封面
下载高清视频
观看高清视频
视频下载器
[DRL] 从 TRPO 到 PPO(PPO-penalty,PPO-clip)
【人工智能基础】第48讲:策略梯度-Reinforce-Actor Critic
[蒙特卡洛方法] 04 重要性采样补充,数学性质及 On-policy vs. Off-policy
[pytorch 强化学习] 05 迷宫环境(maze environment)策略梯度(Policy Gradient)求解
[优化算法] 梯度下降、共轭梯度、牛顿法、逆牛顿法(BFGS)
[pytorch 强化学习] 01 认识环境(environment,gym.Env)以及 CartPole-v0/v1 环境
[personal chatgpt] 从 RoPE 到 CoPE(绝对位置编码,相对位置编码,Contextual Position Encoding)
[linux tools] tmux 分屏(终端复用器)
[pytorch 强化学习] 13 基于 pytorch 神经网络实现 policy gradient(REINFORCE)求解 CartPole
[pytorch distributed] 01 nn.DataParallel 数据并行初步
[矩阵分析] LoRA 矩阵分析基础之 SVD low rank approximation(低秩逼近)
[pytorch] 激活函数,从 ReLU、LeakyRELU 到 GELU 及其梯度(gradient)(BertLayer,FFN,GELU)
[机器学习理论] 霍夫丁不等式(hoeffding's inequality)到 UCB
[蒙特卡洛方法] 01 从黎曼和式积分(Reimann Sum)到蒙特卡洛估计(monte carlo estimation)求积分求期望
[pytorch] [求导练习] 03 计算图(computation graph)及链式法则(chain rule)反向传播过程
[pytorch 强化学习] 11 逐行写代码实现 DQN(ReplayMemory,Transition,DQN as Q function)
[LLMs 实践] 20 llama2 源码分析 cache KV(keys、values cache)加速推理
[pytorch] [求导练习] 04 前向计算与反向传播与梯度更新(forward,loss.backward(), optimizer.step)
[pytorch] [求导练习] 06 计算图(computation graph)细节之 retain graph(multi output/backwar)
[RLHF] 从 PPO rlhf 到 DPO,公式推导与原理分析
[数学!数学] 最大似然估计(MLE)与最小化交叉熵损失(cross entropy loss)的等价性
[动手写bert系列] 01 huggingface tokenizer (vocab,encode,decode)原理及细节
[概率 & 统计] kl div kl散度的计算及应用(pytorch)
[pytorch 强化学习] 10 从 Q Learning 到 DQN(experience replay 与 huber loss / smooth L1)
【python 运筹优化】scipy.optimize.minimize 使用
[概率 & 统计] Thompson Sampling(随机贝叶斯后验采样)与多臂老虎机
[pytorch] [求导练习] 01 sigmoid 函数自动求导练习(autograd,单变量,多变量 multivariables 形式)
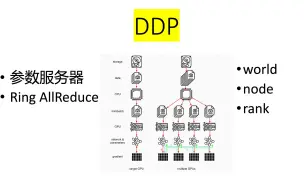
[pytorch distributed] 02 DDP 基本概念(Ring AllReduce,node,world,rank,参数服务器)
[概率 & 统计] KL 散度(KL div)forward vs. reverse
[QKV attention] flash attention(Tiling与重计算),operation fused,HBM vs. SRAM
[leetcode reviews] 01 计算思维与刷题方法
[pytorch] 激活函数(梯度消失)sigmoid,clamp,relu(sparse representation,dying relu)
[pytorch] nn.Embedding 前向查表索引过程与 one hot 关系及 max_norm 的作用
[generative models] 概率建模视角下的现代生成模型(生成式 vs. 判别式,采样与密度估计)
[动手写神经网络] 01 认识 pytorch 中的 dataset、dataloader(mnist、fashionmnist、cifar10)
[番外] float16 与 bf16 表示和计算细节
[强化学习基础 03] 多臂老虎机(Multi-Armed Bandit)与 UCB
[pytorch distributed] torch 分布式基础(process group),点对点通信,集合通信
[LangChain] 01 基础入门,LCEL 、Tool Use、RAG 以及 LangSmith
[personal chatgpt] LLAMA 3 整体介绍(与 LLama 2 的不同?)