V
主页
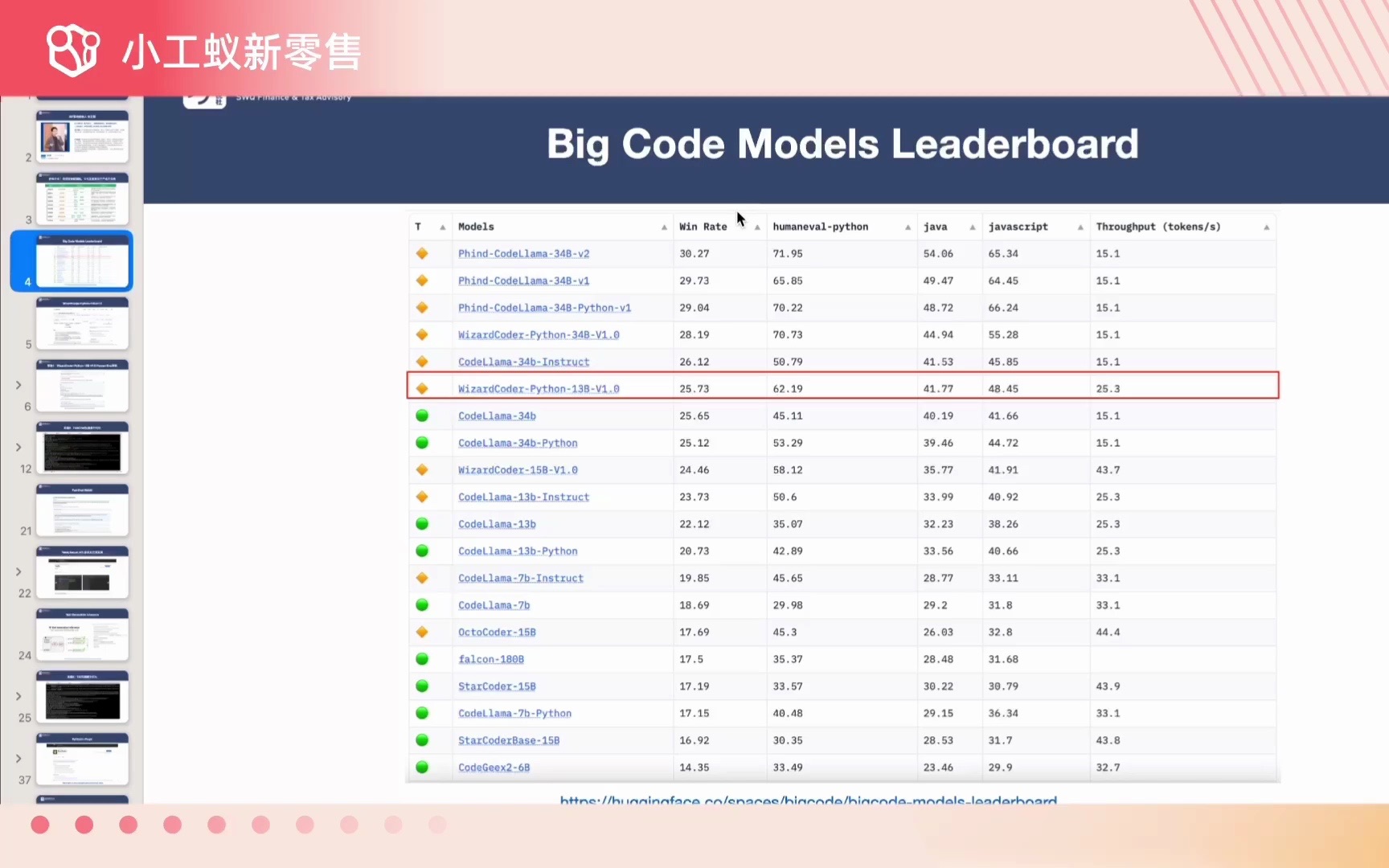
开源最强生成代码大模型WizardCoder开箱评测,性能究竟如何?
发布人
开源最强生成代码大模型WizardCoder开箱评测,性能究竟如何?#小工蚁
打开封面
下载高清视频
观看高清视频
视频下载器
几百次大模型LoRA和QLoRA 微调实践的经验分享
开源SQLCoder模型生成SQL代码能力超越GPT3.5 #小工蚁 #bigcode
清华智谱开源视觉大模型 CogVLM,可免费商用
AutoLabel:自动标注,比人快100倍,准确度和人一样!#小工蚁 #大语言模型
基于LLaMA-2微调中文大模型 千元预算,效果媲美主流大模型
清华发布CodeGeeX2生成代码大模型,它性能究竟如何? #小工蚁 #清华 #codegeex
开源AI生成声音和音乐大模型AudioLDM2 #小工蚁
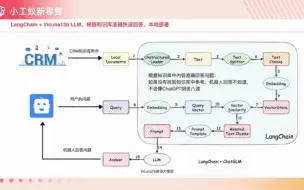
打造智能客服:LLM和本地 知识库的完美协同原理
AIGC生成代码大模型如何选择?
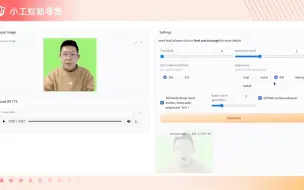
开源数字人项目SadTalker升级 v0.0.2版本功能介绍和演示
M3E中文文本嵌入模型:替代OpenAI text-embedding-ada-002的最佳选择
利用OpenAI的GPT-4训练的微软小模型,是如何成为最强开源模型的?
Jamba开源模型性能超越 Mixtral8*7B 采用最先进混合架构
RAG和LLM原先知识发生冲突时,大模型会怎么做?#小工蚁
大语言模型的技术细节 分布式训练和推理(3/3)
企业大语言模型用什么GPU H100/A100还是4090? #小工蚁
清华开源ChatGLM2-6B安装使用 手把手教程,轻松掌握
企业如何构建自己的ChatGPT 中文LLM大模型和微调方法推荐
llama.cpp大神实现投机采样,让大模型推理性能直接翻倍 #小工蚁
北大开源法律大模型ChatLaw:让法律问题不再复杂 #小工蚁 #ChatLaw
如何让SadTalker数字人更自然?最佳实践参数详细讲解 #小工蚁 #sadtalker
训练大语言模型LLM 如何定义自己训练数据集?#小工蚁
PDF文档文字、表格混排自动识别,增强RAG应用准确度 #小工蚁
BCE Embedding开源大模型 RAG应用准确度提升关键
如何通过种子任务自动生成数据 训练自己的ChatGPT
多模态Embedding开源模型 Visualized BGE #小工蚁
使用LangSmith可视化分析Langchain开发LLM应用 #小工蚁
Meta开源CodeLlama代码大模型性能超越GPT3.5 #小工蚁
探索Mistral 7B英文开源最强大模型滑动窗口注意力算法
xTTS开源文字转声音模型,支持16种语言,支持声音克隆
多模态RAG检索增强生成2种实现方式 #小工蚁
了解大语言模型技术细节(1/3)
用LLM从文本中自动提取数据 生成表格的新算法效率提升110倍
LLM大型语言模型如何进行微调? RLHF强化学习代码解读
Vicuna模型实验和演示 英文LLM最强开源模型之一
Huggingface开源新框架Candle让大模型运行在各种设备上 #小工蚁 #huggingface
StarCoder开源代码AI模型微调成编程助手
中文ChatGLM-6B预训练模型 5.2万提示指令微调演示
腾讯开源LlaMA Pro增强LLM性能 新方法,打造行业模型 #小工蚁
MiniCPM-2B和MoE-8x2B模型 开源最强“小模型” #小工蚁