V
主页
skybox2带模型发布,360度的全景图模型更新。
发布人
- skybox2带模型发布,360度的全景图模型更新。
打开封面
下载高清视频
观看高清视频
视频下载器
Udio发布1.5版本,更好的音质,关键指导以及混音
手机端2秒跑文生图模型
sai公开最新ai生成3d模型,SV3D
最新最快的人体姿势估计,yolo nas pose,比目前最好的人体检测快一倍。
转推,100%纯ai制作
转推,ai动画利用cn控制animatediff第一帧。
luma ai更新首尾帧功能,可以通过2张图片生成中间帧
adobe推出视频高清放大videogigagan
Autodesk推出bernini实验性生成式ai,根据文本2d图像或素体生成多功能3d形状
SDXL1.0发布宣传片
《解限机》桌面动态壁纸现已发布
转推,gen3生成初音未来动画
gpt+ai绘画+ai建模+ai视频genmo chat,目前看来非常有潜力的一款aigc工具,利用语言模型引导进行aigc创作,包括文生图,文生视频以及…
阿里pai公开Easy Animate:基于transformrr架构高性能长视频生成框架
Drivate Gaussian Avatar,利用高斯泼溅生成人物形象模型,并且动作可控
清华联合上海ailab的重绘模型:powerpaint!利用任务提示学习高质量的多功能图像绘制
脸书发布语音引擎产品voicebox,对标tts引擎
Live2Diff:基于视频扩散模型中单向注意力的直播翻译,demo运行于4090
转推ai动画,利用controlnet dwpose控制animatediff
转推,3dvr换装
【SDXL8G优化训练,脚本更新】最新Lora训练AI高级教程13
【SDXL大模型训练教程(上)】最新AI高级教程14
腾讯联合多个大学推出omg,多概念图像生成框架,支持人物和画风 LoRA共用。它还可与 InstantID 结合使用,为每个 ID 生成一张图片,从而生成多个…
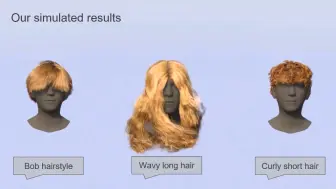
HAAR:基于三维股线的人类发型文本条件生成模型https://haar.is.tue.mpg.de/
英伟达公开采样调节器AlignYouSteps
elevenlab推出生成式音乐ai,无后期处理效果一览
SDXL下载量前50大模型全面评估。12个大类11个prompt维度评估。
去中心化gpu训练大型模型可能!通过4个gpu集群远程同步参数训练10亿参数大模型
文庙参观中喵,小威的daye参观走姿,emmmmm🤔
(ai编程)覆盖50w行代码,上限500wtokens的专业编程语言模型ltmhttps://magic.dev/blog/ltm-1
DynVideo-e,稳定替换背景风格与人物
转推,胶佬狂喜。dalle3生成ai模型深度图在blender里拼接成功
unity推出的ai工具muse宣传片,除了文生图外还有文生贴图,文生动作以及场景等
adobe开源AT-EDM:注意力驱动的扩散模型的免训练效率增强,降低40%计算成本
stablity ai的ceo刚刚发布了新的svd预告视频,画质和效果大幅提升
腾讯音乐莱拉实验室公开museV,基于视觉条件并行去噪的无限长度和高保真虚拟人视频生成,亮点在其并行去噪算法。
【转油管】sd模型ai生成3d模型原理解释。
magicavatar,字节跳动最新ai论文,多模态人像生成动画视频
FreeU,优化unet权重缩放比例获得更好画面表现效果。目前已有插件可安装。
转油管,ai笔记本电脑,加速生成式ai速度