V
主页
权重初始化新方法:大模型权重初始化小模型,训练省时又涨点!
发布人
需要论文/代码的同学可以 关注后看私信或添加以下: https://www.bilibili.com/read/cv21673469
打开封面
下载高清视频
观看高清视频
视频下载器
LLaMa最新变种:全新LLM后预训练方法来袭!
AI时代变迁:性能媲美大模型,小模型是最新热门吗?
【水论文必看!】特征融合12种变态魔改方法
即插即用,显著降低Transformer计算量的模型轻量化方法
如何1小时训练你的多模态大模型用于下游任务
35年首次证明!神经网络泛化能力荣登《Nature》
必将成为发论文神器:大模型结合小模型,10种最新创新思路
大模型都在用的注意力加速优化Flash Attention到底稳定吗?#Wasserstein距离 #数值偏差
人人都可用的涨点神器:高效&可微分变换的全新激活函数
不到256KBMemory就实现了单片机上的神经网络训练,开销不到PyTorch的千分之一(附原文和代码)
小波变换+注意力机制再登Nature!这15种创新突破,你还不知道?
Transformer 很 难 ? 50行代码手撸一个!(上)
神经网络是黑盒吗?用神经网络等同决策树打破这层理解
RFAConv助力YOLOv8 再涨2个点
小样本学习登Nature:计算效率高170倍,彻底起飞!附16种前沿创新方法
最新几何Transformer模型登上Nature子刊!预测实现近10倍的速度提升,14种最新思路
腾讯AI Lab开源全新注意力机制:助力视觉任务疯狂涨点!
医学图像分割必看U-Net新变体:无缝集成,猛涨20个mloU!
聚类算法新突破:K-means聚类改进刷新SOTA,计算吞吐量提高300%!9种创新思路借鉴
Transformer+U-Net全新突破:荣登《Nature》,模型准确率暴涨至99.97%!最新14种创新手法
深度学习新动向:液态神经网络拿下Nature子刊!10种最新创新思路
【全126集】目前B站最系统的Transformer教程!入门到进阶,全程干货讲解!拿走不谢!(神经网络/NLP/注意力机制/大模型/GPT/RNN)
陈丹琦组提出解释大模型的新方法:将权重转为代码
大模型浪潮下的时间序列预测:透彻了解2种热门工作方法,4篇优秀论文
简单模型的神-全新可解释性方法!为神经网络激活找到更可解释的基
以13B的基座模型击败恐怖如斯的GPT4,北大凭什么?
显式考虑异质性不流行了? 神经片状传播才是主流!最有实力的异构图神经网络来袭!
上交全新架构:完全取代DPSA,超过ConvNeXt、CSWin
UNet编码器新传播方案:加速41%采样速度,几乎不影响效果
最新大模型+时空预测工作汇总!借鉴26种目前最主流创新思路
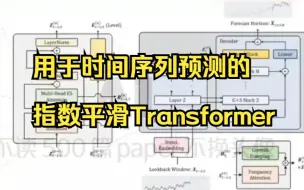
用于时间序列预测的 指数平滑Transformer
刚上线,星标就达1.4k的神经网络可视化神器,配备最新教程+200篇神经网络必读顶会
小波变换+CNN绝了!误差直降89.4%! 超好涨点,你上你也行
今年读到最震撼的一本书《因果关系》,9.4高分必读!
【CV】比SAM快30倍的SAM-Lightening来了!推理一张图仅需7毫秒
涨点神器:全局动态性+局部动态性,让模型性能倍增!10种创新思路
高端的大模型往往只需要最朴素的压缩方式:通用提示压缩高达480倍!
百里挑一“萃取”数据精华!上海AI实验室开源发布高质量语料
GPT-o2推理超神,GPT-o1为何被 “冷落”?大模型训练
最新黑盒效应?用数学来论证神经网络训练会涌现傅立叶特征