V
主页
03 什么是预训练(Transformer 前奏)
发布人
什么是预训练,预训练能做什么呢?我们通过图片的预训练来介绍预训练在干一件什么事情,之后在慢慢深入到 BERT 这个预训练模型中去。 博客配套视频链接: https://space.bilibili.com/383551518?spm_id_from=333.1007.0.0 b 站直接看 配套 github 链接:https://github.com/nickchen121/Pre-training-language-model 配套博客链接:https://www.cnblogs.com/nickchen121/p/15105048.html
打开封面
下载高清视频
观看高清视频
视频下载器
10 Transformer 之 Self-Attention(自注意力机制)
11 Self-Attention 相比较 RNN 和 LSTM 的优缺点
1001 Attention 和 Self-Attention 的区别(还不能区分我就真的无能为力了)
03 Transformer 中的多头注意力(Multi-Head Attention)Pytorch代码实现
09 Transformer 之什么是注意力机制(Attention)
06 BERT 的本质,预训练出一个认识世界的小孩子,及下游任务改造
06 Word2Vec模型(第一个专门做词向量的模型,CBOW和Skip-gram)
12 Transformer的掩码自注意力机制,Masked Self-Attention(掩码自注意力机制)
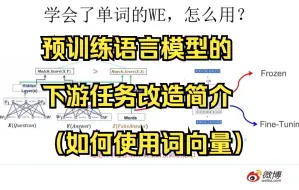
07 预训练语言模型的下游任务改造简介(如何使用词向量)
19 Transformer 解码器的两个为什么(为什么做掩码、为什么用编码器-解码器注意力)
20 Transformer 的输出和输入是什么
02 没人用的 GPT 原来这么容易理解
深度学习技术与应用_25_预训练模型_01
01 GPT 和 BERT 开课了(两者和 Transformer 的区别)
02 Transformer 中 Add&Norm(残差和标准化)代码实现
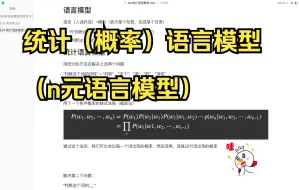
04 统计语言模型(n元语言模型)
14 Transformer之位置编码Positional Encoding (为什么 Self-Attention 需要位置编码)
69 BERT预训练【动手学深度学习v2】
4 种大模型训练方法:预训练、微调、指令微调、增强学习
04 BERT 之为什么要做语言掩码模型(MLM)?
预训练和直接训练的区别是什么?
13 Transformer的多头注意力,Multi-Head Self-Attention(从空间角度解释为什么做多头)
05 神经网络语言模型(独热编码+词向量 Word Embedding 的起源)
16 Transformer的编码器(Encodes)——我在做更优秀的词向量
通俗易懂理解大模型预训练和微调
学术妲己拯救你做一个优秀的学术裁缝,没有继承且无法复现论文模型怎么办?
BERT (预训练Transformer模型)
预训练的优势和劣势有哪些?
生成式预训练Transformer(GPT)详解 | 深度学习 - 第5章 - 3Blue1Brown
深度学习论文实验中的其中一大注意点-预训练权重究竟加还是不加?
15 Transformer 框架概述
【研1基本功 (真的很简单)注意力机制】手写多头注意力机制
大模型的训练流程是什么?详解大模型预训练和微调间区别 #大模型 #微调
18 Transformer 的动态流程
Transformer和BERT看不懂来这里,告诉你他们的前世今生,必能懂
03 BERT,集大成者,公认的里程碑
04 Transformer 中的位置编码的 Pytorch 实现(徒手造 Positional Encoding)
Pytorch预训练图像分类模型识别预测【两天搞定AI毕设】
强烈推荐!台大李宏毅自注意力机制和Transformer详解!
使用预训练模型