V
主页
RAC:从视频中重建可动画的3D模型
发布人
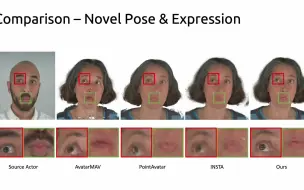
由于需要 3D 扫描、繁琐的配准和手动装配,而且很难扩展到任意类别,因此构建可动画的 3D 模型具有挑战性。最近,可微分渲染提供了从单目视频获取高质量 3D 模型的途径,但这些仅限于严格的类别或单个实例。我们提出了 RAC,它可以从单目视频构建类别 3D 模型,同时解开实例和运动随时间的变化。引入三个关键思想来解决这个问题:(1) 通过优化将骨架专门化为实例,(2) 一种潜在空间正则化方法,鼓励跨类别共享结构,同时维护实例细节,以及 (3) 使用 3D 背景模型将物体从背景中解开。我们表明,可以
打开封面
下载高清视频
观看高清视频
视频下载器
清华大学提出GPS-Gaussian:立即合成任何未见过的角色的新颖视图,无需任何微调或优化
GaussianAvatars:带有 Rigged 3D Gaussian 的逼真头部头像
YOLOv11多模态 结合CFT模块 融合可见光+红外光双输入
实时人体动作捕捉!清华大学&OPPO新作:融合单目图像和稀疏IMU信号以进行人体动作捕捉
谁懂啊......博士第六年还没发Paper是一种什么样的体验?
你的第一篇SCI写了多久?
Transformer+目标检测:CV领域超好出论文的方向!源码复现+模型精讲+论文解读,迪哥带你轻松搞定论文创新点!DETR/YOLO/计算机视觉
VIVE3D:使用 3D 感知 GAN 进行独立于视点的视频编辑
如何系统地深入机器学习,深度学习,计算机视觉领域并应用于医学图像分割处理?
【200集付费】一口气学完回归算法、聚类算法、决策树、随机森林、神经网络、贝叶斯算法、支持向量机、神经网络等十二大机器学习算法一次性学完!
研一刚入学,从未接触过神经网络python也是才开始学,现在导师要我做LSTM,我应该去学什么?
Text2Tex:通过扩散模型进行文本驱动的纹理合成
你们都是用什么办法,在不想学习的时候如何逼迫自己学习?
人工智能从零入门学习路线图
阿里巴巴团队又整新活!MotionShop:用虚拟3D人代替视频中人的运动的应用
3D人脸生成新工作!AniPortraitGAN:从 2D图像生成可动画的3D肖像,真丝滑!
真正的科研是应该是什么样的?
香港中文大学+腾讯AI视频提出DynamiCrafter!!! 使用视频扩散先验使开放域图像变成动画,更好的动态、更高的分辨率、更强的连贯性!
奶龙识别之龙图也是龙
每天压力太大了!可以把科研压力转移给导师吗?
ICCV 2023 视频抠图神器!影子都能抠掉!Meta新作OmnimatteRF:3D背景建模大显神威
AI写论文网站测评!aicheck、文心一言、豆包等写论文效果怎么样?
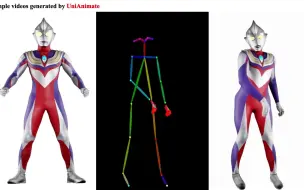
华科联合中科大和阿里巴巴共同提出UniAnimate:驱动单张图片跳舞,结果逼真
做科研应该花时间专门补相关基础知识还是一边做科研一边补所缺的知识?
你都知道哪些科研上最忌讳的事情?
深度学习调参有哪些技巧?
博士生每天科研时间是多久?
完爆YOLOv11!Transformer+目标检测新算法性能无敌,狠狠拿捏CV顶会
谷歌重磅新作ReconFusion:利用扩散先验进行3D重建!性能强悍!
YOLO11改进-项目YOLO11Pro介绍-持续更新【YOLO11原创改进推荐】
直接抄她的代码,就是最好的学习方法!!
AI教父Geoffrey Hinton 对话 Joel Hellermark: 当模型规模最够大,人工智能就可以有创造力
超全超简单!一口气刷完YOLO、SSD、Faster R-CNN、Fast R-CNN、Mask R-CNN、R-CNN等六大目标检测常用算法!真的比刷剧还爽!
大家写深度学习代码的时候,都是怎么检查代码错没错的?
原理代码讲解|多尺度感知融合模块 多头混合卷积 2024一区Top 特征融合【V1代码讲解040】
YOLO模型又更新了?迪哥全面精讲YOLOv11原理及其代码,带你了解最新YOLO模型!
惊呆了!FED-NeRF:在动态NeRF上实现人脸视频编辑
科研大佬把这个问题“深度学习论文该如何不看作者或他人代码自主复现?”怎么解决讲清楚啦!我直呼牛掰啊!
深度学习attention机制中的Q,K,V分别是从哪来的?
如何入门机器学习?有哪些值得分享的学习心得?