V
主页
whisperx项目,这个项目主要基于 faster-whisper 和 pyannote-audio 实现了可以区分说话人的语音识别功能。
发布人
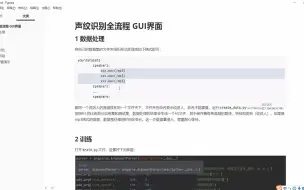
whisper x 项目,这个项目主要基于 faster-whisper 和 pyannote-audio 实现了可以区分说话人的语音识别功能。 地址:https://github.com/m-bain/whisperX.git import whisperx # 导入whisperx模块 import gc # 导入gc模块,用于垃圾回收 device = "cuda" # 指定设备为CUDA(显卡加速) audio_file = "/content/en3_resampled.wav" # 指定音频文件路径 batch_size = 16 # 批处理大小,如果GPU内存不足则减小这个值 compute_type = "float16" # 计算类型为浮点数16位,如果GPU内存不足则改为整数8位(可能会降低准确性) # 1. 使用原始whisper进行转录(批处理) model = whisperx.load_model("large-v3", device, compute_type=compute_type) # 加载模型 # 将模型保存到本地路径(可选) # model_dir = "/path/" # model = whisperx.load_model("large-v2", device, compute_type=compute_type, download_root=model_dir) audio = whisperx.load_audio(audio_file) # 加载音频文件 result = model.transcribe(audio, batch_size=batch_size) # 使用模型进行转录 print(result["segments"]) # 打印转录结果的分段(未对齐之前) # 如果GPU资源不足,则删除模型 # import gc; gc.collect(); torch.cuda.empty_cache(); del model # 2. 对齐whisper输出 model_a, metadata = whisperx.load_align_model(language_code=result["language"], device=device) # 加载对齐模型 result = whisperx.align(result["segments"], model_a, metadata, audio, device, return_char_alignments=False) # 对齐转录结果 print(result["segments"]) # 打印对齐后的转录结果的分段 # 如果GPU资源不足,则删除模型 # import gc; gc.collect(); torch.cuda.empty_cache(); del model_a # 3. 分配说话者标签 diarize_model = whisperx.DiarizationPipeline(model_name='pyannote/speaker-diarization-3.1', use_auth_token='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', device=device) # 加载分离说话者模型 # 如果已知最小/最大说话者数量,则添加到参数中 diarize_segments = diarize_model(audio) # 进行说话者分离 # diarize_model(audio, min_speakers=min_speakers, max_speakers=max_speakers) result = whisperx.assign_word_speakers(diarize_segments, result) # 为转录结果分配说话者 print(diarize_segments) # 打印说话者分离结果 print(result["segments"]) # 打印分配了说话者ID的转录结果
打开封面
下载高清视频
观看高清视频
视频下载器
whisper实时语音识别
【SRT字幕工具箱】当Whisper识别的字幕不会智能断句时,试试这个方法!
【Whisper-WebUI】本地部署一键包 离线识别字幕
语音转字幕神器Fast-Whisper-GUI
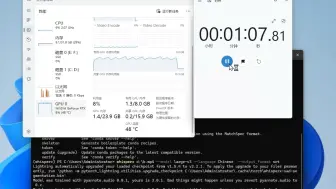
whisperX largev3 测试:30分钟不间断谈话用时103秒,平均每秒处理88字
【Whisper-Webui】一键包 批量离线制作字幕文件 自带large-v3模型
faster_whisper部署详细教程 | 可内网部署ASR | 开源ASR
Whisper 开源语音转字幕软件,集成显卡也能跑
如何用 faster-whisper 做一个超低延迟语音聊天机器人
Whisper | Faster Whisper | 语音识别 | 可内网部署的ASR
一个离线运行的本地语音识别转文字服务,输出json、srt字幕带时间戳、纯文字格式
300元Tesla P4, 让Whisper语音识别提升加速10倍,完美的语音加速卡
实时语音识别部署教程 | 可离线部署的实时语音识别项目
基于faster whisper实现实时语音识别项目语音转文本python编程实现
【深度学习】基于whisper的语音识别
基于whisper实现的前端调用麦克风进行语音识别
基于faster whisper的实时语音识别项目
可本地部署的实时语音识别项目
VAD优化Whisper,faster-whisper-webui一个转录速度起飞的开源语音识别项目,转录效果很好
分享一个Comfyui的一键真人转动漫视频工作流
基于faster_whisper的实时语音识别
【AI主播-STT篇】接入 faster-whisper,本地识别,不用魔法,不用密钥,省钱(但是费电
使用VAD优化过的whisper语音识别开源项目faster-whisper-webui,免费开源,福利多多
whisper实时语音识别-普通话效果
能离线使用的语音识别工具:Buzz,使用OpenAI Whisper神经网路,正确率高
whisper-jax最详细的安装教程 | 一个号称比whisper快70倍的语音识别项目 | 免费开源的语音识别项目
免费的whisper模型与音视频翻译4-subtitle edit-本地大模型语音识别转写
语音转文字,本地部署,Fast whisper免费分享
油管大V用whisper实现“零延迟”语音转写,真的吗?🤔️
声纹识别系统GUI(说话人识别)
whisper,whisper-jax和faster whisper速度对比
纯内网部署Whisper | 竟然可以这么简单在无外网环境下安装Whisper
新一代 Kaldi: 说话人识别+VAD+语音识别之 Python API
语音识别OpenAI Whisper微调,识别中文地方方言-潮州话
五分钟!学会Window上都可运行的高精度语音识别模型Faster-whisper,完全免费开源
OpenAI 发布新版开源语音识别模型 whisper-large-v3
faster_whisper封装成一个api接口
五分钟!快速体验Qwen-Audio语音识别,阿里最新开源的大语音模型
免费的whisper模型与音视频翻译1-whisper desktop
免费开源语音转文字Whisper快速搭建,可生成字幕,媒体人的福音