V
主页
057Spark的WordCount程序环境准备3
发布人
057Spark的WordCount程序环境准备3
打开封面
下载高清视频
观看高清视频
视频下载器
014大数据经典面试题-求最大的N个数
Flink跟Spark存在的必要性,有哪些?
004大数据分布式计算引擎设计实现剖析01
大数据求偶v2 BFB 杭州
001Spark课程引言01
025Spark 执行引擎解析02
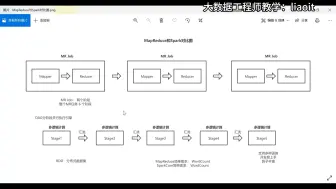
016MapReduce 框架核心流程01
001Flink课程介绍01
038Spark基础使用01
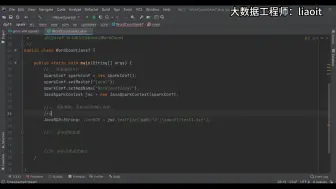
050Spark编写WordCount
056Spark的WordCount程序环境准备2
055Spark的WordCount程序环境准备1
05Xshell和Xftp的安装
009MapReduce v2的缺陷及解决方案
2024Spark-1-绪论
大数据求偶(bfb)
054Spark上次课程回顾
050Flink集群搭建03
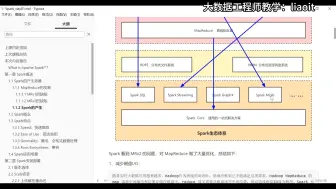
012Spark的产生03
004MapReduce v1的缺陷01
035Flink流式计算引擎基础理论03
027Spark 执行引擎解析04
034Flink流式计算引擎基础理论02
002Spark课程引言02
大数据求偶
028Spark 执行引擎解析05
010Spark的产生01
059Spark的Java7版本WordCount编写01
01大数据研发工程师课前环境搭建说明
033Flink流式计算引擎基础理论01
023Spark应用场景01
030Spark正式安装01
052Flink集群搭建05
026Spark 执行引擎解析03
046Flink 架构设计实现和应用模块分工05
020MapReduce 框架核心流程05
051Flink集群搭建04
062Spark的Java7版本WordCount编写04
053Flink集群搭建06
007MapReduce 执行引擎解析01