V
主页
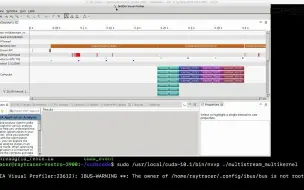
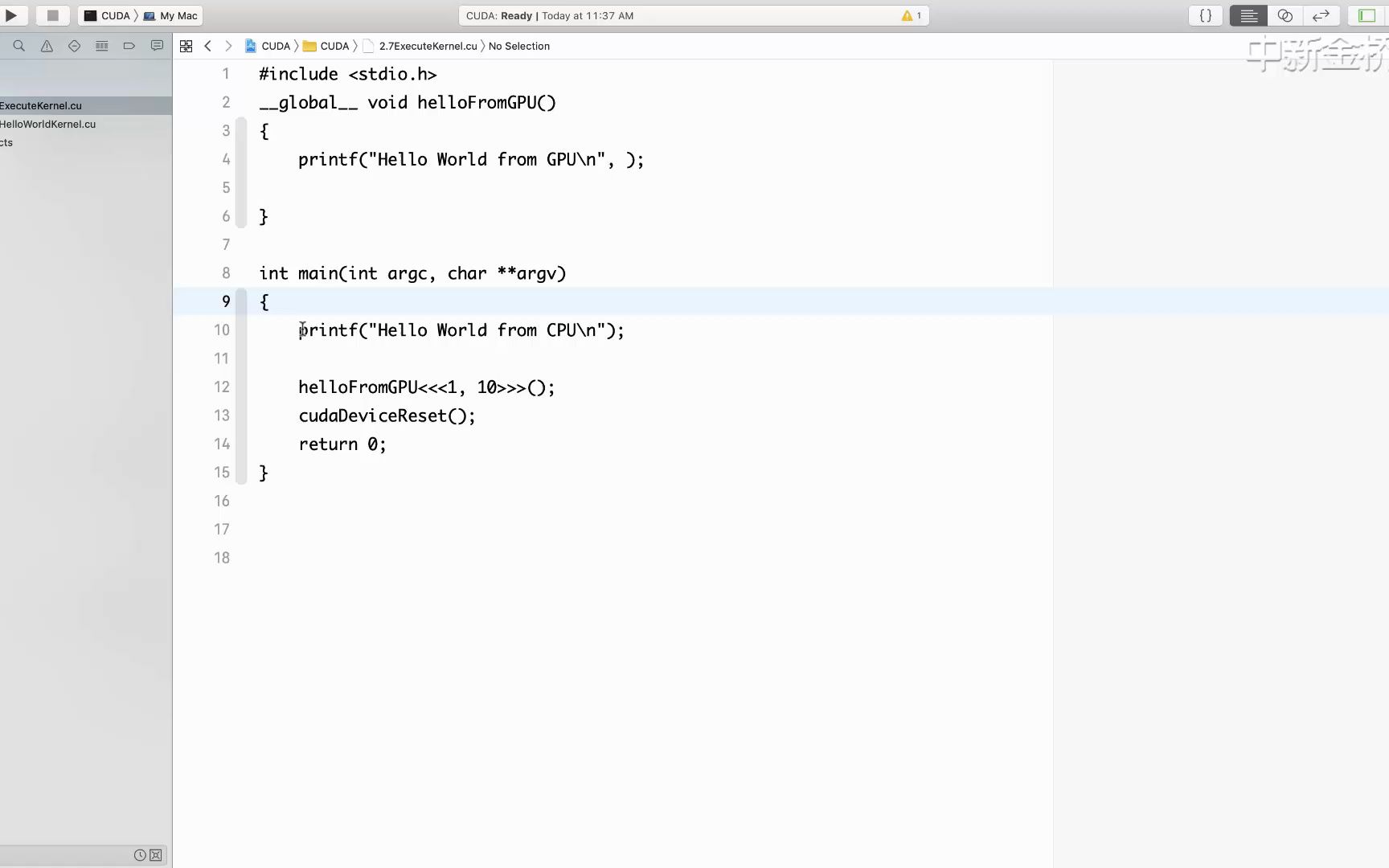
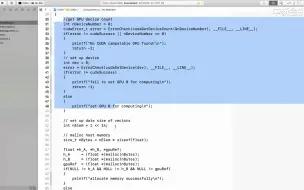
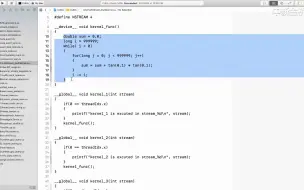
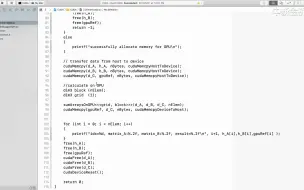
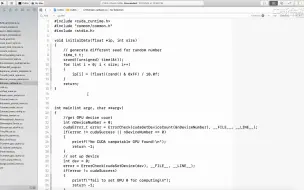
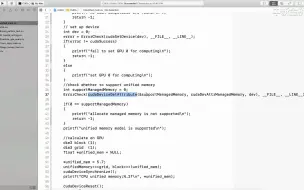
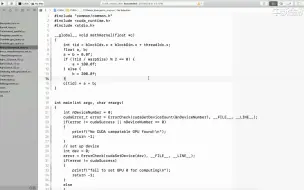
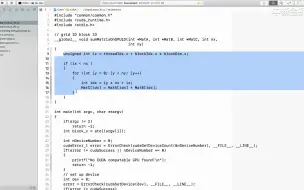
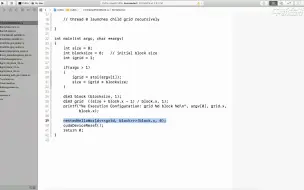
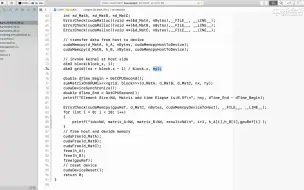
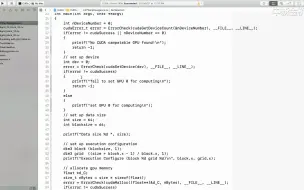
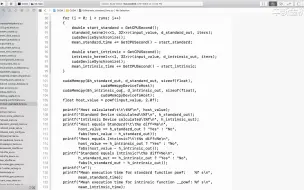
2.7 CUDA内核函数执行
发布人
打开封面
下载高清视频
观看高清视频
视频下载器
5.3 单精度和双精度
2.21 监测内核执行时间
4.12 多流多内核执行
2.20 内核矩阵加法
2.6 CUDA内核函数
3.8 统一虚拟地址
3.5 全局内存
4.19 流回调函数
2.22 nvprof监测内核执行时间
4.11 GPU内核并发检测
1.3 CUDA介绍
4.8 流执行顺序
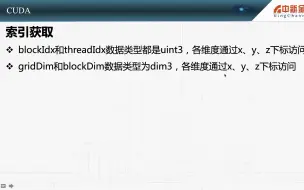
2.23 用网格和块索引数据
3.9 统一内存空间
2.35 nvprof分析线程束和内存读写
2.33 内存指令并行性需求
6.5 内核入口断点
4.14 Visual Profiler分析多内核执行
3.23 共享内存屏障
5.9 MAD指令优化
2.29 线程束分支特点
3.3 本地内存和共享内存
5.1 底层指令优化
2.36 邻域并行计算
2.25 一维网格和块配置
3.1 GPU内存结构
2.41 动态并行HelloWorld
2.8 获取线程索引
2.26 二维网格和一维块配置
2.11 GPU架构
3.4 常量内存
2.15 二进制兼容性
2.27 线程束分支
5.8 内置函数PTX代码分析
2.4 nvcc工作流程
2.14 PTX兼容性
2.37 间域并行计算
4.18 内核和数据拷贝并行
5.12 原子操作的性能损失
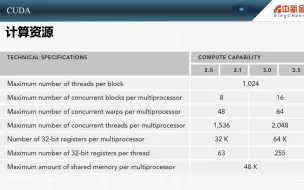
2.30 线程束计算资源分配