V
主页
【珍藏】从头开始用代码构建GPT - 大神Andrej Karpathy 的“神经网络从Zero到Hero 系列”之七
发布人
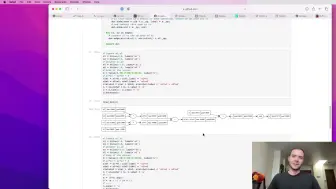
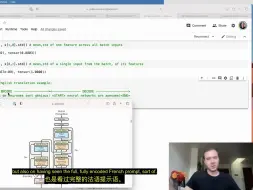
Andrej Karpathy大神 亲自讲解如何从零开始用python代码构建一个最小的nanoGPT(基于莎士比亚全文本训练集,对标GPT2)异常珍贵的材料,对于搞大模型的技术同学绝对不容错过。 【天空之城原创翻译制作,谢绝转录】 该视频于2023年1月18号发出,2月初Andrej即宣布回归OpenAI,nanoGPT显然是他自己深入理解GPT原理的产物。这视频半年播放量300w...这只是纯技术纯码农视频,可见有多受欢迎。 早就想翻译这个视频到中文世界,城主理解很多码农不一定能听全程英文的内容。但这个翻译绝对是城主这么多视频最最难的一次,超S级的难度,各种中英混杂,代码符号混杂,中断过两次,这次终于整理校对完成。 =Andrej的原视频注释: 链接: - 视频的Google Colab:https://colab.research.google.com/drive/1JMLa53HDuA-i7ZBmqV7ZnA3c_fvtXnx-?usp=sharing - 视频的GitHub存储库:https://github.com/karpathy/ng-video-lecture - nanoGPT仓库:https://github.com/karpathy/nanoGPT - 我的网站:https://karpathy.ai - 我的推特:https://twitter.com/karpathy - 我们的Discord频道:https://discord.gg/3zy8kqD9Cp 补充链接: - Attention is All You Need论文:https://arxiv.org/abs/1706.03762 - OpenAI GPT-3论文:https://arxiv.org/abs/2005.14165 - OpenAI ChatGPT博客文章:https://openai.com/blog/chatgpt/ - 我用来训练模型的GPU来自Lambda GPU Cloud,我认为这是在云中启动按需GPU实例并通过ssh访问的最佳和最简单的方式:https://lambdalabs.com。如果您更喜欢在笔记本中工作,我认为今天最简单的路径是Google Colab。 我们遵循论文“Attention is All You Need”和OpenAI的GPT-2/GPT-3,构建了一个生成式预训练转换器(GPT)。我们讨论了它与风靡全球的ChatGPT的联系。我们观察GitHub Copilot(其本身是一个GPT)帮助我们编写一个GPT(套娃:smile:)。 章节: 00:00:00 介绍:ChatGPT、Transformer、nanoGPT、莎士比亚,基线语言建模,代码设置 00:07:52 阅读和探索数据 00:09:28 分词,训练集/验证集划分 00:14:27 数据加载器:批量数据块 00:22:11 最简单的基线:二元语法模型,损失,生成 00:34:53 训练二元语法模型 00:38:00 将代码移植到脚本中构建“自注意力” 00:42:13 版本1:用for循环平均过去的上下文,聚合的最弱形式 00:47:11 自注意力的技巧:矩阵乘法作为加权聚合 00:51:54 版本2:使用矩阵乘法 00:54:42 版本3:添加softmax 00:58:26 小的代码清理 01:00:18 位置编码 01:02:00 视频的关键部分:版本4:自注意力 01:11:38 注1:注意力作为交流 01:12:46 注2:注意力没有空间概念,在集合上操作 01:13:40 注3:批处理维度之间没有交流 01:14:14 注4:编码器块与解码器块 01:15:39 注5:注意力 vs 自注意力 vs 交叉注意力 01:16:56 注6:“缩放”自注意力。为什么除以sqrt(head_size)构建Transformer 01:19:11 在网络中插入单个自注意力块 01:21:59 多头自注意力 01:24:25 Transformer块的前馈层 01:26:48 残差连接 01:32:51 LayerNorm(及其与之前批量规范化的关系) 01:37:49 放大模型!创建一些变量,添加dropout关于Transformer的说明 01:42:39 编码器vs解码器vs两者(?)Transformer 01:46:22 快速浏览nanoGPT,批量多头自注意力 01:48:53 回到ChatGPT,GPT-3,预训练与微调,RLHF 01:54:32 结论 00:57:00 抱歉!应该是“未来的标记不能交流”,不是“过去的”。 01:20:05 应该使用head_size进行归一化,不是C
打开封面
下载高清视频
观看高清视频
视频下载器
【Andrej Karpathy:从零开始构建 GPT 系列】
【热门】强的离谱,油管大佬从零开始复现GPT,太细致了!
大神手把手教学实现GPT(zero to hero系列) Let's build GPT: from scratch in code
【百万好评】 Clean Code(整洁代码)国外技术大佬终极讲解教程,价值3W实战教学,让你的编程能力突飞猛进(中英字幕)
【重制版】【中英字幕】【Andrej Karpathy】详细介绍了神经网络和反向传播构建微梯度 -0-
Neural Networks: Zero to Hero 神经网络:从入门到精通
Open AI传奇研究员Andrej Karpathy的新课,教你理解和构建GPT Tokenizer
【自制中英字幕】【Andrej Karpathy】让我们从头开始,在代码中构建GPT
【自制中英字幕】【Andrej Karpathy】语言建模的详细介绍——构建makemore -3-
手把手从头实现GPT by Andrej Karpathy
(超爽中英!) 2024公认最好的【吴恩达机器学习】教程!附课件代码 Machine Learning Specialization
[中配] 从零实现GPT (NanoGPT) - Andrej Karpathy
【中配】神经网络与反向传播的详解:构建微小的微分引擎(Micrograd) - Andrej Karpathy
Andrej Karpathy(安德烈·卡帕西)大佬带你从零开始构建GPT!
高中生自己实现了GPT!?
【中英字幕】Andrej Karpathy | 详解神经网络和反向传播(基于micrograd)
【精校】大神Andrej Karpathy 大模型讲座 | 构建makemore 系列之五(完结):构建一个WaveNet
【精校】AI大神Andrej Karpathy构建MakeMore课程之五:构建WaveNet【中英】
karpathy 分享从马尔代夫水屋凌晨写代码到大模型神话:llm.c的崛起之路
【自制中英字幕】【Andrej Karpathy】语言建模的详细介绍——构建makemore -2-
【精校】“让我们重现GPT-2(1.24亿参数)!”AI大神Andrej Karpathy最新4小时经典教程 【中英】
我敢保证这是B站最全的ChatGPT教程!包含ChatGPT、GPT-1、GPT-2、GPT-3的详细讲解!5个小时带你搞定难懂的知识点!赶紧收藏学习了!
前Tesla 无人驾驶团队首席开发官 Andrej Karpathy 解析FSD
【自制中英字幕】【Andrej Karpathy】语言建模的详细介绍——构建makemore -1-
【入门到精通】一口气学完回归算法、聚类算法、决策树、随机森林、神经网络、贝叶斯算法、支持向量机等十大机器学习算法!全程干货,比刷剧还爽!AI人工智能丨深度学习
【Andrej Karpathy】中文字幕|Let's build the GPT Tokenizer
小型GPT代码逐行讲解
Andrej Karpathy《让我们复现GPT-2 (124M)|Let's reproduce GPT-2 (124M)》中英字幕
国外大佬从零图解transformer,一目了然!
我保证这是最全的【ChatGPT讲解+GPT算法讲解源码复现】教程!三个小时刷新你的认知!保姆级教程,学不会来找我!-ChatGPT、GPT算法、GPT-2源码
【中英字幕】【Andrej Karpathy】让我们创建 GPT Tokenizer
斯坦福 GPT/Transformer 原理介绍 (中英文双字幕)
【熟】代码美学:最佳模式——依赖注入
OpenAI大神Andrej Karpathy教你从零构建GPT系列所使用的分词器 Let's build the GPT Tokenizer(李飞飞高徒)
OpenAI 联合创始人 Andrej Karpathy 在2024年加州大学伯克利分校人工智能黑客马拉松颁奖典礼上的主题演讲
【精校】大神Andrej Karpathy 大模型讲座 | 构建makemore 系列之一:讲解语言建模的明确入门
他叫尤雨溪,一个前端,写了一个叫 Vue 的框架。
1. LLM 模型和理论基础
硕士生去搞计算机视觉,是纯纯的脑瘫行为!
【从零实现GPT2 Andrej Karpathy 2024.06.10】OpenAI—中英字幕