V
主页
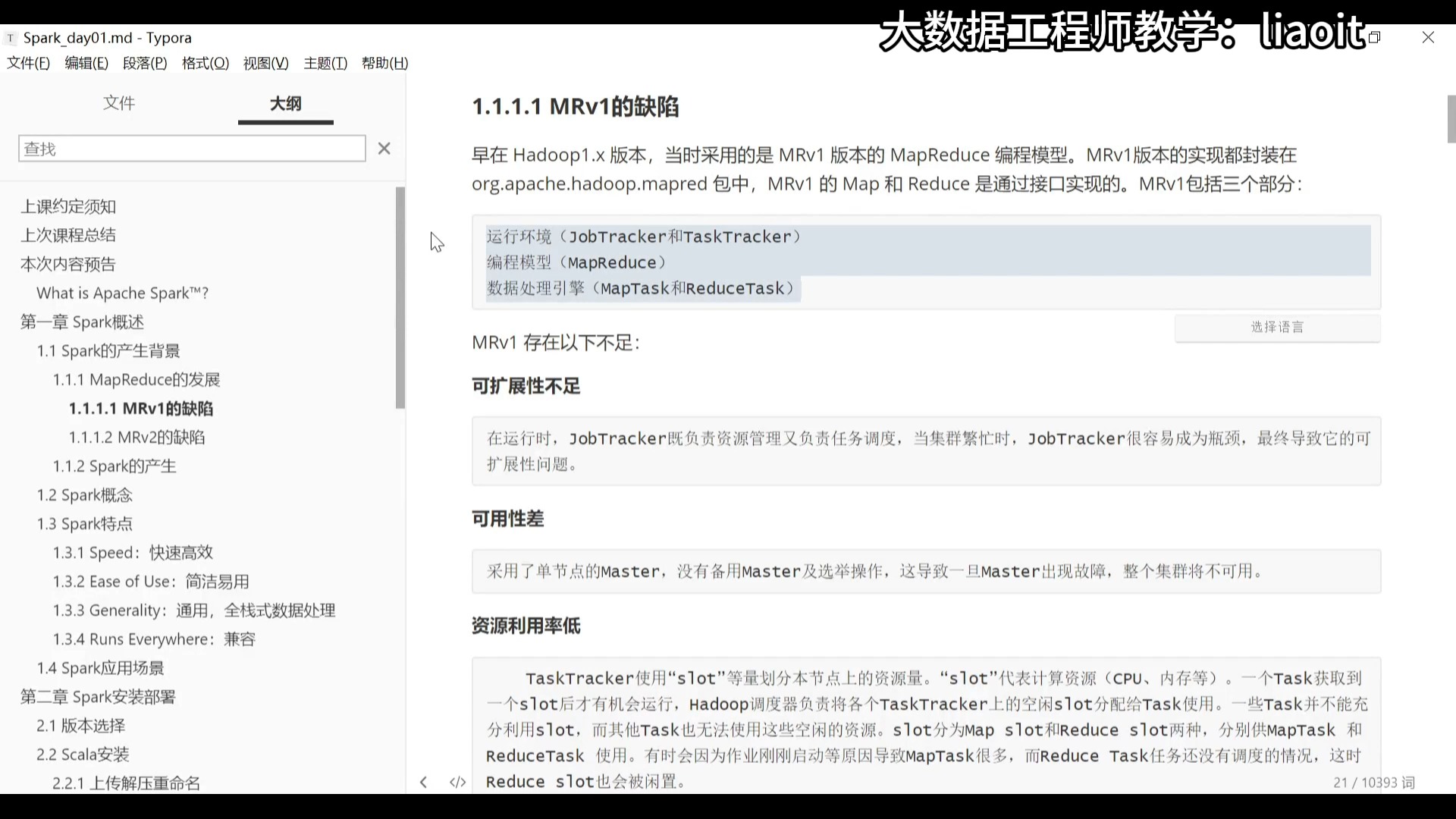
005MapReduce v1的缺陷02
发布人
005MapReduce v1的缺陷02
打开封面
下载高清视频
观看高清视频
视频下载器
0090MapReduce优缺点
0092MapReduce核心思路2
004MapReduce v1的缺陷01
0089MapReduce概念9
0085MapReduce概念5
009MapReduce v2的缺陷及解决方案
0084MapReduce概念4
0082MapReduce概念2
0083MapReduce概念3
0087MapReduce概念7
0088MapReduce概念8
03VMware安装CentOS7操作系统引导过程
008MapReduce v2的缺陷01
0086MapReduce概念6
05Xshell和Xftp的安装
04CentOS7安装过程中的一些必要性的设置
0091MapReduce核心思路1
0093MapReduce核心思路3
09JDK的安装
0097MapReduce核心思路7
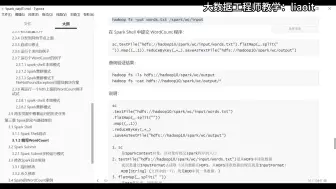
11Hadoop集群格式化与启动
049Spark基础使用12
019MapReduce 框架核心流程04
006MapReduce v1的缺陷03
12Hadoop启动之后页面访问
024Spark应用场景02
0009什么是Hadoop(一)
杜克大学《应用Python数据工程(3课全)|Applied Python Data Engineering》中英字幕
06Xshell连接虚拟机
0081MapReduce概念1
0074HDFS读数据流程1
001Spark课程引言01
031Spark正式安装02
010Spark的产生01
016MapReduce 框架核心流程01
0070HDFS心跳机制3+HDFS安全模式1
0075HDFS读数据流程2
012Spark的产生03
10Hadoop的安装
0046HDFS的API操作4之代码编辑器介绍