V
主页
【ECCV 2022】华为诺亚提出CLIFF:将全帧位置信息带入人体姿势和形状估计
发布人
yt 自顶向下的方法在3D人体姿势和形状估计领域占据主导地位,因为它们与人体检测分离,允许研究人员专注于核心问题。然而,裁剪是它们的第一步,从一开始就丢弃了位置信息,这使得它们无法在原始相机坐标系中准确预测全局旋转。为了解决这个问题,我们建议在这个任务中携带全帧位置信息(CLIFF)。
打开封面
下载高清视频
观看高清视频
视频下载器
【ECCV 2022】POSE-NDF:用神经距离场模拟人体姿势流形
同组博士师兄的结果复现不出来,我应该怎么办??
实时人体动作捕捉!清华大学&OPPO新作:融合单目图像和稀疏IMU信号以进行人体动作捕捉
【ECCV2022】帅,太帅了!联合多目标检测、3D 纹理重建、6D 目标姿态和大小估计的方法
【娘娘捏捏乐】紫禁城的风水养人,必不会叫你玉减香消 #ai #ai视频 #AI视频生成 #甄嬛传十级观众
【颜值对比】诺亚vs诺亚
看了吴恩达的深度学习,看了小土堆的pytorch、李沐的动手学深度学深度学习也看完了!可是啥都看不懂
上海交大和华为提出,2D照片变3D高清多角度动图!
【ICCV 2021】浙大&谷歌:神经场景渲染系统!可操控场景内对象!效果太惊艳!
"将这相簿中的空白 轻轻地填满至尽吧" ai诺亚 「WHITE ALBUM(白色相簿)」
卡通化算法!SIGGRAPH Asia 2022 动漫人脸自由切换,高分辨率视频风格
(决斗)诺亚VS宇宙大爆炸
奥特曼传奇英雄2诺亚的技能
【CVPR 2022】LISA:学习手的隐式形状和外观
当Transformer遇见语义分割!SegFormer:性能更强的语义分割网络!
【ECCV 2022】百度&南洋理工等最新研究:【样式交换】基于样式的发生器可实现强大的面部交换
奈克瑟斯·奥特曼(青年·究极)(Ultraman Nexus Extreme research)
【CVPR 2022】基于稀疏输入视图的神经辐射场的密集深度先验
深度学习调参有哪些技巧?
Niantic Labs提出DiffusioNeRF:使用去噪扩散模型正则化神经辐射场
[ECCV 2024]StructLDM:从 2D 图像集合生成 3D 人类的新范式
微软提出DisCo:生成具有多样化外观和灵活动作的高质量人体舞蹈图像和视频
加州大学重磅新作!SLAHMR:在具有挑战性的野外视频中稳健地恢复人们的全局 3D 轨迹
被点醒了!想学好线代一定不能错过的《线性代数可视化手册》,求所有线代不好的把这12页纸翻烂!MIT大神级教授神书
【ECCV2022】 SimpleRecon 无需 3D 卷积的高质量三维重建方案
谷歌+浙大提出SINE:语义驱动的基于图像的 NeRF 编辑,具有先验引导的编辑场
中国专家的认可!诺贝尔奖获得者丁肇中谈马斯克向其请教问题:今天做不出来的事情不代表明天也做不出来,力挺马斯克!
制作花朵形状的交通灯
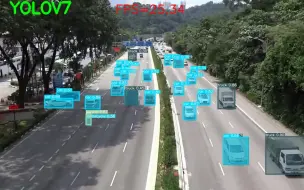
快来看看YOLOV7的效果怎么样吧!
孩子们,诺亚的好大🥵
【CVPR 2022】它会魔法吧?基于光流的端到端视频补全框架 (E2FGVI)
【CVPR 2022】南洋理工大学:具有生成先验的无监督图像到图像翻译
【ICCV 2021】浙大&商汤,基于时序一致性的物体3D姿态检测与跟踪
终于有人把OpenCV讲清楚了,2022B站最好的OpenCV从入门到实战 全套课程(附带课程课件资料+课件笔记)
【Pytorch常用函数手册】Pytorch必备神器,必须收藏!
ICCV 2023 Oral 逆光也清晰!CLIP-LIT:无监督背光图像增强的迭代提示学习
【ECCV 2022】苏黎世联邦理工:LaMAR:AR 的基准本地化和映射
AI变身 男变身女生日宴 人工智能