V
主页
4-spark-算子3大分类
发布人
打开封面
下载高清视频
观看高清视频
视频下载器
42-spark sql-数据写入hive
15-spark-on yarn-client.mp4
13-spark-算子详解03.mp4
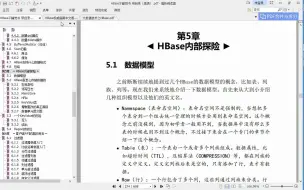
hbase06_-宏观结构及基本概念介绍-
41-spark sql-保存数据的几种方式
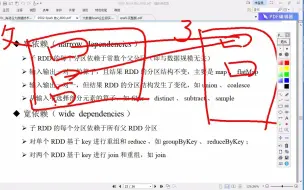
06-spark-宽窄依赖01
02-spark-countbykey
09-spark-任务提交详细流程01
18-spark sql-注册临时表.mp4
hbase21_-26个过滤器-02
scala49_-协变-逆变
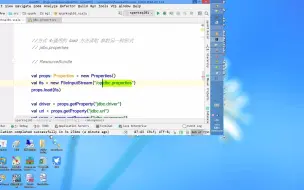
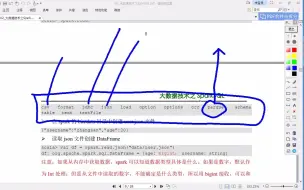
sqoop01-从mysql导出数据到hive
sqoop02-从hive导出数据到mysql
scala46_-隐式转换
05-spark-collectAsMap算子
25-spark sql-加载数据的几种方式02.mp4
scala19_-继承父类的同时调用父类的构造器
scala16_-setter和getter方法
08-spark-RDD依赖的血统关系
07-spark-job的触发提交与task数量的决定因素
hbase22_-26个过滤器-03
scala35_-匿名函数
【七天做完大数据毕设】基于Hadoop、Hive和Spark的当当网图书可视化分析系统 第8小节 可视化大屏
scala03_基础语法01-main函数
14-spark-on yarn-cluster模式01
scala33_-函数与函数指针及引用的关系
sqopp06-1.7版本的增量导入
【七天做完大数据毕设】基于Hadoop、Hive和Spark的当当网图书可视化分析系统 第2小节 数据采集
scala10_数组
hbase29_-结合spark2.x
scala18_-类型转换
zookeeper09-leader选举的10种情况-01
flume02_内部原理
【七天做完大数据毕设】基于Hadoop、Hive和Spark的当当网图书可视化分析系统 第5小节 数据分析
scala06_基础语法04-for循环与if守卫条件
scala41_-常用方法00
Hive 4.x 最新版本之核心基础
19-spark-sql-RDD与DataFrame之间的转换.mp4
基于HDFS的百度云盘-104-新独立访客的思路
scala42_-常用方法02