V
主页
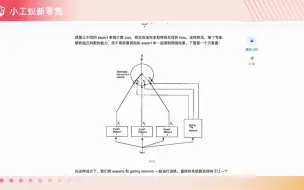
中文版Mixtral-7x8bMoE25GB显存畅玩专家模型,真·超越GPT3.5!#多专家模型
发布人
本次资源:本篇论文+代码 需要的同学请Co我 https://www.bilibili.com/read/cv21673469
打开封面
下载高清视频
观看高清视频
视频下载器
本地+跨平台运行 Mixtral-8x7B MoE大模型 AI推理APP仅2M
微软发布2.7B小模型,碾压谷歌Gemini!性能直接打平比自己大25倍的大模型?
让Mixtral-8*7B模型运行在16GB显存GPU上 #小工蚁
使用Mac Studio跑Mistral AI新出Mixtral-8x7B-MoE大模型速度测试(M2 Ultra 76-core GPU 192GB RAM)
llama.cpp + A40 显卡运行 Mixtral 8x7B MoE 量化模型推理速度记录
超越GPT3.5开源模型Mixtral 真来了,可免费商用
【穷训】2W服务器训练7B模型
Mixtral-8*7B开源模型生产环境部署优化 2块RTX4090 #小工蚁
失业吧、数据分析师!!!魔改chatglm3 、GPT4 国产平替、 代码自动生成 数据自动统计 图表自动生成
2080Ti跑70B大模型!上交新框架让LLM推理增速11倍,一经发布引爆业界
mistral-next:接近gpt-4的欧洲神秘的大模型,比mistral-7*8b还要强大的新一代大模型,在逻辑思维、知识、编程能力整体超越了chatgpt
NVIDIA Tesla V100 16GB专业计算卡改装一体式水冷散热温度狂降40度
【生肉】在Mac+跨设备运行混合专家大模型 Mixtral-8x7B
大语言模型也能多核心?8个7B模型拼接超越ChatGPT|开源免费|Mixtral 8 x 7B 重磅发布|Mistral 7B|本地运行|评测|在线体验
微软语言模型phi-2太离谱
国内大模型基本就是靠两个洋雷锋
大语言模型 - 通义千问1.8B 很赞👍
Mistral:8x7B开源MoE击败Llama 2逼近GPT-4!首个开源MoE大模型发布!也是首个能够达到gpt-3.5水平的开源大模型
用 llama.cpp 跑通 mixtral MoE 模型
PatchTSMixer开源最强多变量 时间序列预测算法
Mistral AI模型 Mixtral 8x7B 如何“以小博大”
VLLM 测试 Mixtral MoE 的 GPTQ 量化版本
对TinyLlama 1.1 B 有点失望
如何知道一个大模型在推理和训练时需要多少显存?
Mixtral开源模型测评跑Agent效果如何
RWKV—部署在本地的AI大模型,只需2G显存!人人都有拥有自己的AI!
零一万物 Yi-34B-Chat 跻身全球权威榜单前列:开源黑马直追 GPT-4!
全网首发:Mixtral 8x7B模型Win下部署教程和演示
只需 24G 显存,用 vllm 跑起来 Yi-34B 中英双语大模型
GPT-4模型架构泄露:1.8万亿参数 混合专家模型 (MoE) 揭秘
【最强开源LLM】Mistral-(8x)7b vs OpenAI GPT-3.5 + SOTA LLMs || RAG性能对比
本地 Mistral 7B 模型 推理(1/2)
国产首个开源MoE大模型DeepSeekMoE 16B #小工蚁
都是48GB显存谁更强?RTX A6000 VS Tesla A40
达到 GPT-4 水平的(伪)开源 LLM 会在 2024 年出现吗?
【AI大模型体验测评系列01】Mixtral-8x7B-Instruct在M1 Pro 32G上的推理速度测试
苹果MLX发布!教你在自己的Mac上运行Lama 70模型,开启AI新时代!
开源最强Mixtral模型是通过 什么算法和工具训练出来的?
【源码分析|修改】Mistral-7B|Llama2-13B实现高级RAG方法
InternLM2可能是目前7B中文开源大模型的天花板