V
主页
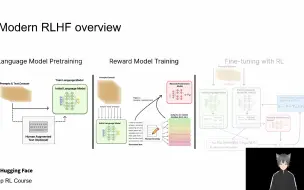
全栈大模型微调框架LLaMA Factory:从预训练到RLHF的高效实现
发布人
全栈大模型微调框架LLaMA Factory:从预训练到RLHF的高效实现 郑耀威,北京航空航天大学博士生 https://github.com/hiyouga/LLaMA-Factory 【NICE十期】
打开封面
下载高清视频
观看高清视频
视频下载器
手把手教你如何使用LLaMA-Factory微调阿里千问 Qwen 大模型
LLaMA-Factory的基本使用与安装
llama-factory-train
【保姆级部署教程】想得到一个属于自己的大模型?快来了解一下LLaMA Factory微调框架,10分钟快速上手,轻松完成大模型高效微调
大模型高效微调框架LLaMA-Factory技术原理解析 | SciSci AI Workshop
开源大模型高效微调流程详解|Llama-Factory零门槛微调大模型|保姆级微调教程
llama3-06 基于llama-factory和自定义数据集进行模型微调
LLaMA-Factory lora微调chatglm3-6b P40显卡
吹爆!全网最通俗易懂的ChatGLM预训练+微调教程,北大博士后手把手带你调用属于自己的对话大模型—ChatGLM!
RLHF训练法从零复现,代码实战,大语言模型训练
【0代码微调大模型】在阿里云上使用LLaMa-Factory
Deita: 用高质量数据在微调中“四两拨千斤”
10分钟打造你个人专属的语言大模型:LLaMA-Factory LLM Finetune
PPO@RLHF ChatGPT原理解析
AntSK保姆级教程4-llamafactory使用教程
Llama3中文增强模型微调和法律大模型微调
LLMLingua: 压缩prompt构造LLMs的语言
LlamaFactory:微调QWe (千问)模型 简单微调多数模型的便捷方法
轻松搞定!LLaMA-Factory让你快速实现大模型训练与评估!
LLAMA-3🦙微调极简教程,微调自己的llama3模型,更少的资源更快的速度
用RLHF的方法解读论语
【chatglm3】(7):大模型训练利器,使用LLaMa-Factory开源项目,对ChatGLM3进行训练,特别方便,支持多个模型,非常方方便
SFT和RLHF的区别是什么?
理解大模型训练的几个阶段 Pretraining,SFT,RLHF
第十课:RLHF
LLM推理加速新范式!推测解码(Speculative Decoding)最新综述
【保姆级教程】6小时掌握开源大模型本地部署到微调,从硬件指南到ChatGLM3-6B模型部署微调实战|逐帧详解|直达技术底层
从零开始训练大模型
RLHF大模型加强学习机制原理介绍
【合集】Llama3本地部署与中文能力微调实战|零门槛零基础部署Llama3大模型|借助Llama-Factory进行高效微调
Windows下中文微调Llama3,单卡8G显存只需5分钟,可接入GPT4All、Ollama实现CPU推理聊天,附一键训练脚本。
RLHF实际上是如何工作的
【7】手写大模型代码(中)( LLM:从零到一)
LLaMA-MoE:基于参数复用的混合专家模型构建方法探索
llama-factory全流程:专为新手设计。
从零开始手搓一个LLM(一)把参数缩减到足够单卡训练的NanoGPT
Transformer的无限之路:位置编码视角下的长度外推
【保姆级教程】使用ChatGLM3-6B+oneAPI+Fastgpt+LLaMA-Factory实现本地大模型微调+知识库+接口管理
部署微调ChatGlm3-6B大模型【小白0到1】
图解llama架构 解读源码实现