V
主页
基于SVD首尾帧进行关键帧插值,进行视频生成
发布人
基于SVD首尾帧进行关键帧插值,进行视频生成 论文:https://arxiv.org/abs/2408.15239 首页:https://svd-keyframe-interpolation.github.io/ 代码:https://github.com/jeanne-wang/svd_keyframe_interpolation.git
打开封面
下载高清视频
观看高清视频
视频下载器
StreamingSVD: 开源丝滑长视频生成
StreamingT2V 最长2分钟视频生成,开源了!
MagicVideo-V2 字节视频生成,多阶段高美感视频生成,为开源,持续关注
Magic-Me:字节最新开源特定人物的AI视频生成,仅需几张图片!
最新视频生成大模型Vchitect-2.0开源,书生筑梦大模型支持生成20秒长度的视频
StoryDiffusion 字节发布角色一致性图像和长视频生成的方法
AniClipart 剪贴画动画生成模型,基于文本到视频先验引导的运动序列框架
LivePortrait 单张图片驱动虚拟人,快手联合高校开源肖像动画模型
AnyDoor 阿里图片区域替换技术,开源了!实现虚拟换衣,页面元素替换!
OpenSora 1.2版本发布,开源!高分辨率,时长达5s。(luma、可灵、即将Gen-3,视频生成又一个热潮)
vividTalk 最新虚拟人合成项目,效果超sadtalker
AniTalker 虚拟人项目,上海交大,AISpeech联合推出即将开源!
MotionClone: AI视频动作克隆框架并可使用文本提示生成新动作
打死我也不删的绘图神器!一个神级科研图表网站,可以生成69种精美论文图表!
ToonCrafter 卡通插值视频生成,香港高校和腾讯AI lab开源项目!
krita AI 一键整合包! 解压即用 解决报错!碾压comfyUI降低门槛!FLUX - CN可用!最灵活的ai绘画软件!
DragAnything 快手联合高校开源,使用实体表示对任何物体进行运动控制
DynamiCrafter 港中文,腾讯,北大开源!更可控,更细节的视频生成模型
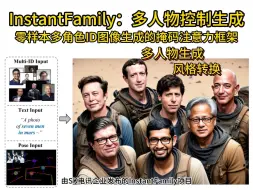
InstantFamily 多人物控制生成,零样本多角色ID图像生成的掩码注意力框架
OOTDiffusion 虚拟换衣项目开源,高度可控且支持全身和半身。
Dynamic Typography SVG 动态字体版式,使得文本更加生动,驱动单字母视频化开源!
MOFA-Video 腾讯联合高校基于SVD多类型控制信号视频生成,开源!
V-Express 单图片虚拟人视频生成,南大和腾讯ailab已开源!
StreamingT2V 最长2分钟视频,基于自回归技术的一致性、动态且可扩展的长视频
LTX Studio保持角色一致性的AI视频生成, 一个可以发挥您想象力的讲故事平台,已开启内测!
EvTexture 视频超分辨率修复技术,中科大联合研究机构开源!
CoTracker,Meta最新开源目标追踪模型,处理遮挡等场景
EMO:Emote Portrait Alive 阿里最新发布,在弱条件下使用音视频扩散模型生成富有表现力的肖像视频
HandRefiner修复扩散模型生成过程中手异常问题,已开源!
ZeST:零样本材质迁移,使用单张图进行图片材质迁移,已开源!
mvcontrolnet canny算子直接生成3D模型!
LUMIERE google最新视频生成技术,引入时空扩散模型,超强视频生成和编辑能力!
PixelsDance扩散模型的视频生成新方法!
Follow-your-click 港科大等高效联合提出,通过简短提示点击进行开放域区域图像动画生成
PhotoMaker:腾讯开源逼真的肖像生成,超高保真度,支持风格迁移,肖像生成等!
EMOPortraits 表情迁移,给定面部表情进行表情迁移,7月开源!
即将开源的AI 3D模型生成
GLIGEN GUI:更加便捷的对扩散模型生图进行控制,界面化开源,结合comfyui
AniPortrait 腾讯开源虚拟人项目,对比阿里EMO,由音频驱动的真实肖像动画合成
DreamTalk 基于扩散模型的虚拟人项目,会唱歌的虚拟人