V
主页
如何入門Langevin Dynamics (Diffusion Model的重要算法)
发布人
https://www.youtube.com/watch?v=QKj4pmZXKMY
打开封面
下载高清视频
观看高清视频
视频下载器
Cudamode Lecture 22: Hacker's Guide to Speculative Decoding in VLLM
Research Track 8:比较关注的一些论文
Cudamode Lecture 13: Ring Attention
Cudamode Lecture 1 How to profile CUDA kernels in PyTorch
FasterTransformer
探讨TensorRT加速AI模型的简易方案 — 以图像超分为例
Cudamode Bonus Lecture: CUDA C++ llm.cpp
Accelerating Convolution with Tensor Cores in CUTLASS
Cudamode Lecture 6:Optimizing Optimizers
CUDA MODE Lecture 12: Flash Attention
不写一行代码,开发一款属于自己的游戏
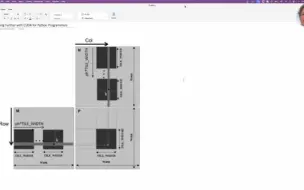
cudamode Lecture3: Getting Started With CUDA for Python Programmers
cudamode Lecture 8: CUDA Performance Checklist
CudamodeLecture 17: NCCL
Cudemode Lecture 14: Practitioners Guide to Triton
cudamode Lecture 9: Reductions
Cudamode Lecture 15: CUTLASS
cudamode lecture7 Advanced Quantization
Cudamode Lecture 11: Sparsity
Cudamode Lecture 5: Going Further with CUDA for Python Programmers
Training a LLaMA in your Backyard:fine-tuning Very Large Models on Consumer Hard
Cudamode Lecture 16: On Hands Profiling
Cudamode Lecture 4 Compute and Memory Basics
Lightning Talk: The Fastest Path to Production: PyTorch Inference in Python
Cudamode Lecture 19: Data Processing on GPUs
cuda mode2: pmpp book ch1-3
Cudamode Lecture 10: Build a Prod Ready CUDA library
Introducing ExecuTorch from PyTorch Edge: On-Device AI Stack and Ecosystem, and
Into Generative AI with PyTorch Lightning 2.0
Accelerating Pytorch networks with native CUDA graphs support | MICHAEL CARILLI
Accelerating Generative AI - Christian Puhrsch & Horace He, Meta
Cudamode Fusing Kernels
CUDAGraph in a Partial Graph World
3D虚拟衣服
The Triton language
Harnessing NVIDIA Tensor Cores An Exploration of CUTLASS & OpenAI triton
从谣言到“有图有真相”,我们该怎么对抗AI的深度伪造?
CUTLASS: Python API, Enhancements, and NVIDIA Hopper
Accelerating Large Language Models via Low-Bit Quantization
酒鬼嵌入式,每天一个小知识12-cache如何加速程序运行!