V
主页
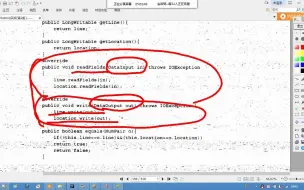
16-spark-持久化算子
发布人
打开封面
下载高清视频
观看高清视频
视频下载器
12-spark-计算圆周率01
scala14_的构造器
11-spark-算子详解01
10-spark-spark Context 对象的初始化
hbase06_-宏观结构及基本概念介绍-
14-spark-算子详解03-0000.mp4
1-spark-生态系统
02-spark-countbykey
Hadoop理论基础-03-配置Linux主机名称与IP映射
2-spark-对比Hadoop优势与特点
08-spark-RDD依赖的血统关系
25-spark sql-加载数据的几种方式02.mp4
hbase27_-spark结合
09-spark-任务提交详细流程01
3-spark-RDD的5个特征
hbase09_-三次定位查询.mp4
hbase24_-布隆过滤器.avi
scala44_-模式匹配02
flume02_内部原理
kafka01_-比对消息队列-01
scala11_多维数组
41-spark sql-保存数据的几种方式
scala39_-闭包
scala46_-隐式转换
10-spark-区分action算子的3个技巧
hbase05_-基本操作命令
19-spark-sql-RDD与DataFrame之间的转换.mp4
kafka11_-索引文件的构建方式
Hadoop理论基础-16-Java API操作hdfs
Hive_08_sql案例01_hive的删除操作
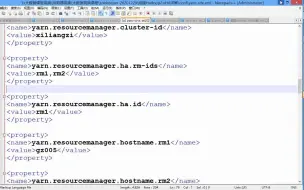
zookeeper02-Hadoop HA-02
Hive_36_hive-分桶
hbase17_-客户端api.mp4
基于HDFS的百度云盘-101-百度云盘-就是埋点+nginx日志
zookeeper04-特征、应用场景、配置参数介绍
基于HDFS的百度云盘-106-echarts报表工具展示每天的pv值
scala05_基础语法03-for循环-to与until的区别
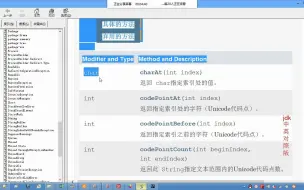
Hadoop理论基础-27-String类常用方法.mp4
Hadoop理论基础-45-MapReduce的二次排序.mp4
scala07_基础语法05-定义函数的语法格式