V
主页
京东 11.11 红包
大数据 YARN 调度策略
发布人
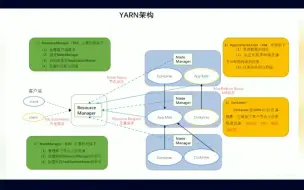
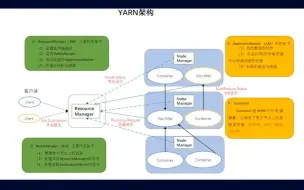
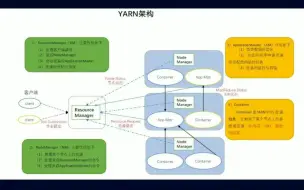
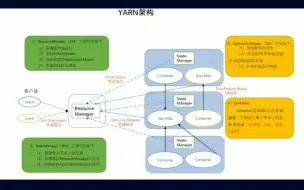
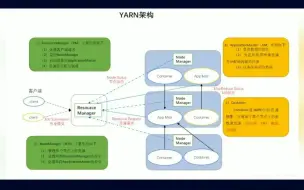
YARN(Yet Another Resource Negotiator)是Apache Hadoop生态系统的一个关键组件,用于集群资源管理和作业调度。YARN调度策略是指YARN如何有效地管理集群资源并调度作业以实现高效的资源利用和作业执行。 YARN调度策略主要涉及以下几个方面: 1、资源分配策略:YARN通过资源管理器(ResourceManager)对集群资源进行管理和分配。资源分配策略包括容器的资源配额分配和调度算法。其中,容器资源配额分配决定了每个应用程序或作业可以使用的资源量,可以基于队列、用户、应用程序等进行配置。调度算法决定了如何分配可用资源给等待中的应用程序或作业。 2、调度器选择:YARN提供了不同的调度器,如Capacity Scheduler、Fair Scheduler和Dominant Resource Fairness Scheduler等。不同的调度器使用不同的调度策略和算法,以满足不同的需求。例如,Capacity Scheduler支持队列的概念,可以为不同队列分配不同的资源配额,并使用先进先出(FIFO)或公平共享(Fair Share)等调度算法。 3、优先级调度:YARN支持设置作业或应用程序的优先级,以便根据其重要性或紧急程度进行调度。优先级调度策略允许高优先级的作业获得更多的资源,以保证其尽快完成。 4、预留资源:YARN还支持预留资源的概念,允许某些应用程序或作业在集群中保留一定比例的资源,以便在需要时立即使用。这有助于提高关键任务的执行效率。 5、队列管理:YARN的调度器通常支持队列的概念,可以根据不同的队列配置不同的资源配额和调度策略。队列管理策略可以帮助实现不同应用程序或用户之间的资源隔离和公平共享。 需要注意的是,YARN调度策略的配置和设置取决于具体的应用场景和需求。根据集群的规模、作业的特点以及对资源利用和作业性能的要求,可以选择适合的调度策略和调度器进行配置。
打开封面
下载高清视频
观看高清视频
视频下载器
大数据 HDFS 工作原理
大数据 YARN 优先级调度
大数据 YARN 调度器
大数据 YARN 组件
Nginx 负载均衡调度策略
大数据 YARN 队列管理
大数据 HDFS 写数据策略
大数据 RM YARN 高可用机制
大数据 YARN 预留资源
大数据 YARN 容器介绍
大数据 YARN ResourceManager 组件
大数据之Hadoop
大数据 HDFS NameNode 高可用实现原理
大数据 HDFS 中的 Checkpoint 机制
什么是Spark的调度器,它的调度模式有哪些?
大数据 HDFS HA JournalNode的作用
大数据 YARN ResourceManager HA 选举机制
大数据 HDFS NameNode 之间心跳检查
大数据 HDFS Editslog 为什么需要合并成 FSimage
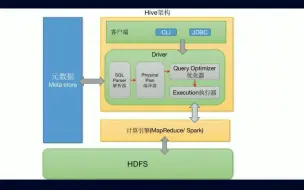
Hive 4.x 最新版本之核心基础
【七天做完大数据毕设】基于Hadoop、Hive和Spark的当当网图书可视化分析系统 第7小节 可视化系统
大数据 hive metastore 与 hivesever2 关系
什么是大数据
大数据 HDFS NN 格式化的作用
什么是Azkaban的日志管理策略?
大数据 HDFS DataNode 数据倾斜的原因
Hadoop HDFS HA 服务启动顺序
Hadoop HDFS ZKFC 存储机制
大数据 MapReduce 介绍
动态刷新配置 之后api获取到配置没变
一副漫画让你一分钟了解YARN三种队列调度器
Hadoop-HA 架构与原理
【七天做完大数据毕设】基于Hadoop、Hive和Spark的当当网图书可视化分析系统 第1小节 项目介绍
大数据 HDFS 组件
大数据 HDFS DataNode 数据倾斜解决方案
老司机带你了解什么是大数据
大数据数仓 Hive
工作流任务调度器 Azkaban
【七天做完大数据毕设】基于Hadoop、Hive和Spark的当当网图书可视化分析系统 第2小节 数据采集
Hadoop技术应用课程实录