V
主页
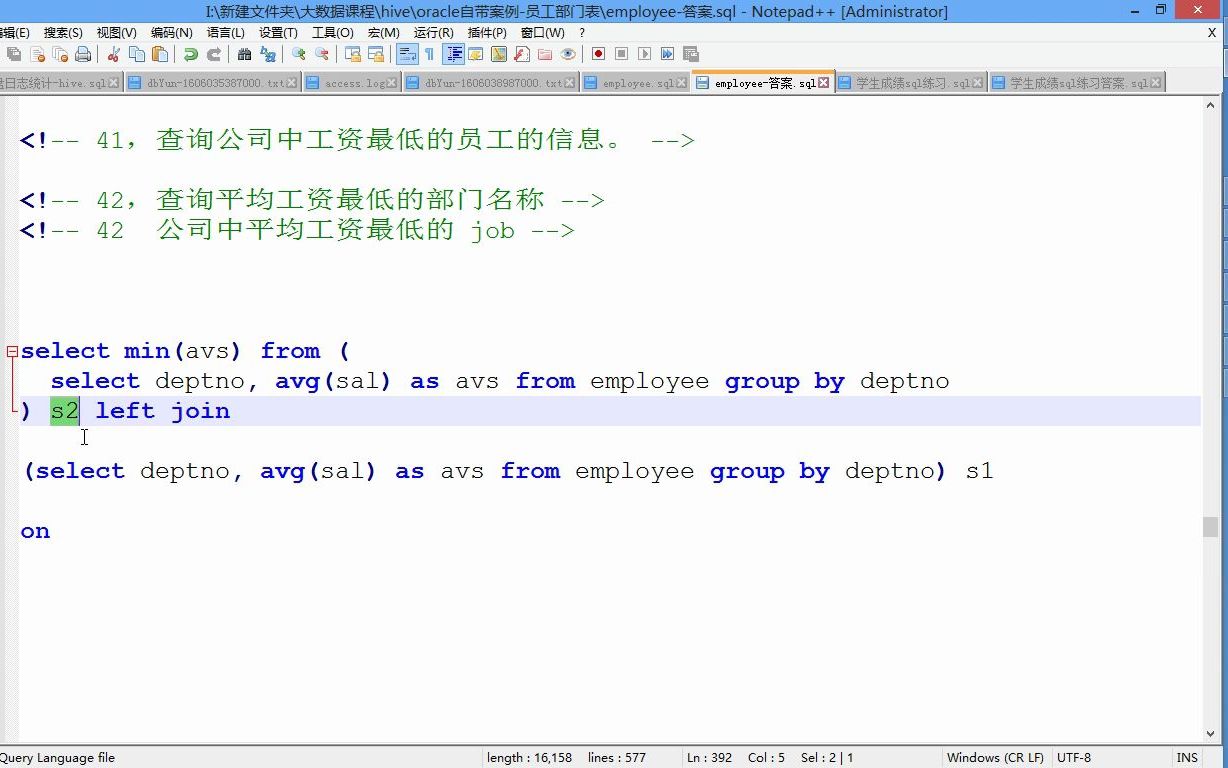
Hive_31_hive-查询平均工资最低的部门名称
发布人
打开封面
下载高清视频
观看高清视频
视频下载器
【七天做完大数据毕设】基于Hadoop、Hive和Spark的当当网图书可视化分析系统 第1小节 项目介绍
Hive_01_hive简单介绍
Hadoop理论基础-64_idea搭建hadoop集群.mp4
【Spark+Hive+hadoop】基于spark+hadoop贴吧-微博热门交流平台数据分析舆情系统 大数据毕设 计算机毕业设计 —免费完整实战教学视频
基于HDFS的百度云盘-104-新独立访客的思路
【七天做完大数据毕设】基于Hadoop、Hive和Spark的当当网图书可视化分析系统 第8小节 可视化大屏
ambari安装-71-ambari安装介绍01
scala43_-模式匹配01
flume01_使用场景
基于HDFS的百度云盘-100-百度云盘-定时上传nginx日志
【七天做完大数据毕设】基于Hadoop、Hive和Spark的当当网图书可视化分析系统 第6小节 数据同步
基于HDFS的百度云盘-91-局部刷新验证码.mp4
【Spark+Hive+hadoop】基于spark+hadoop大数据空气质量数据分析预测系统 大数据毕设 计算机毕业设计 —免费完整实战教学视频
Hive_03_hive数据类型
zookeeper07-leader的选举01
ambari安装-74-ambari离线安装04.mp4
【七天做完大数据毕设】基于Hadoop、Hive和Spark的当当网图书可视化分析系统 第7小节 可视化系统
Hive_17_sql案例10_sql分页去重查询.mp4
基于HDFS的百度云盘-80-基于hdfs的百度云盘存储
Hive_22_sql案例15_缴费总次数.mp4
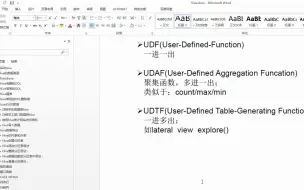
Hive_38_hive-内置函数大全
Hadoop理论基础-34-数据排序.mp4
Hadoop理论基础-60_类的加载机制.mp4
【七天做完大数据毕设】基于Hadoop、Hive和Spark的当当网图书可视化分析系统 第2小节 数据采集
scala42_-常用方法02
Hadoop理论基础-24-统计每天的平均气温.mp4
Hive_33_hive-any-all
整合flume、hive、sqoop的百度云盘项目-06--统计每小时每天每月的新的独立访客
Hadoop理论基础-22-统计每天的平均气温
基于HDFS的百度云盘-102-统计PV值输出到mysql表
Hive_28_hive-三个排名函数的区别
基于HDFS的百度云盘-84-git代码的提交与更新-03.mp4
Hive_09_sql案例02_查询教师部门并去重
Hive_12_sql案例05_hive练习.mp4
zookeeper10-leader选举的10种情况02
整合flume、hive、sqoop的百度云盘项目-08--整合flume拦截器
基于HDFS的百度云盘-87-百度云盘-spring项目环境搭建
Hadoop理论基础-61_反射机制.mp4
Hive_14_sql案例07_hive分组函数02.mp4
【七天做完大数据毕设】基于Hadoop、Hive和Spark的当当网图书可视化分析系统 第4小节 数据清洗