V
主页
大模型RLHF从PPO推导DPO再推导SimPO,公式推导
发布人
大模型RLHF从PPO推导DPO再推导SimPO,公式推导
打开封面
下载高清视频
观看高清视频
视频下载器
全网最通俗易懂,大模型偏好对齐RLHF从PPO推导DPO再推导simPO
3.PPO公式推导DPO
4.DPO改进版simPO
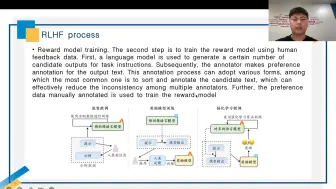
2.RLHF人类偏好对齐PPO
4..DPO训练为什么内容会变长,DPO内容冗余
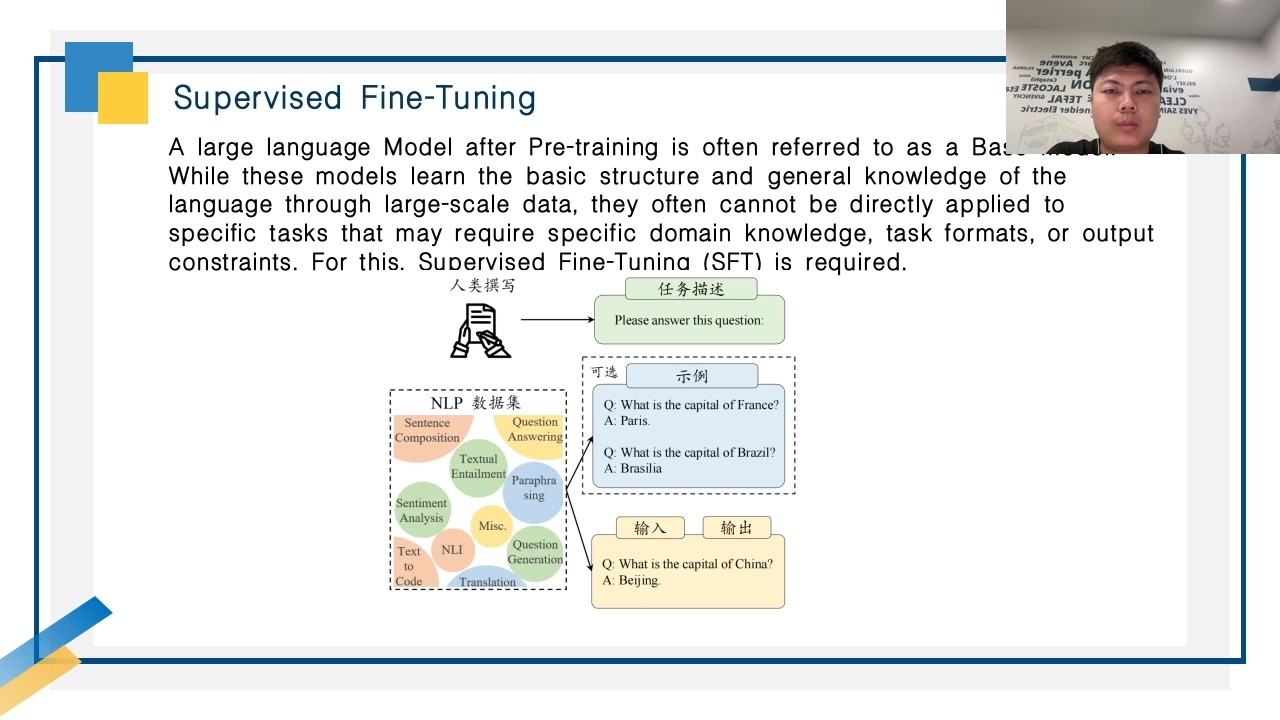
2.大模型训练监督微调SFT
2.使用torch训练一个LSTM模型
1.LSTM循环神经网络介绍
2.使用torch训练一个卷积神经网络
2.训练一个torch模型保存成numpy格式
3.使用numpy手写LSTM神经网络推理
1.大模型训练工具和环境安装llama factory
3.lora模型与原模型合并与推理
3.重写numpy模型在嵌入式平台运行
1.LLM的训练过程
1.多层感知机介绍
1.卷积神经网络介绍
3.使用numpy在嵌入式运行卷积神经网络
4.numpy卷积神经网络使用多线程加速
51单片机红外遥控控制继电器点亮氛围灯
我们试飞成功了【亚特迪斯号】,迪迦奥特曼-科幻进入现实
鸾鸟空天母舰一号验证机,试飞成功!南天门计划,启动!
穿越5300公里,为了找到世界上最大的鲨鱼,我造了一台水下飞行翼!