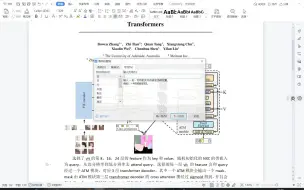
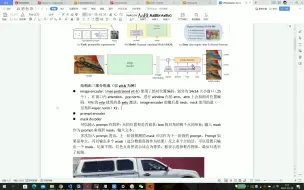
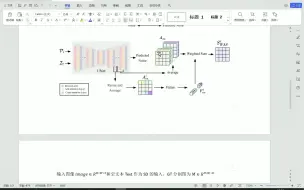
V
主页
京东 11.11 红包
蛋仔派对:萝卜头抱着巨型炸弹想要摧毁蛋仔岛,结果没想到是个哑弹
发布人
蛋仔派对:萝卜头抱着巨型炸弹想要摧毁蛋仔岛,结果是个哑弹
打开封面
下载高清视频
观看高清视频
视频下载器
maskdino
segformer和pvt v1v2和swin v1v2和acfnet、ocrnet区别
StructToken : Rethinking Semantic Segmentation with Structural Prior
SeaFormer: Squeeze-enhanced Axial Transformer for Mobile Semantic Segmentation
Segvit
llama-adapter v2
Dreaming to Distill: Data-free Knowledge Transfer via DeepInversion
Tip-Adapter: Training-free Adaption of CLIP for Few-shot Classification
Understanding the Failure of Batch Normalization for Transformers in NLP
segment anything
Hard Prompts Made Easy: Gradient-Based Discrete Optimization for Prompt Tuning a
Personalize Segment Anything Model with One Shot
Implicit Sample Extension for Unsupervised Person Re-Identification
Pose-guided Feature Disentangling for Occluded Person Re-identification Based on
Rethinking Semantic Segmentation: A Prototype View
GaitSet: Cross-view Gait Recognition through Utilizing Gait as a Deep Set
Open-vocabulary Semantic Segmentation with Frozen Vision-Language M
SLIME:SEGMENT LIKE ME
SegGPT: Segmenting Everything In Context
high quality entity segmentation(ICCV2023)
Learning with Recoverable Forgetting
Prompt Tuning Inversion for Text-Driven Image Editing Using Diffusion Models
Negative Samples are at Large: Leveraging Hard-distance Elastic Loss for Re-iden
Fine-Grained Semantically Aligned Vision-Language Pre-Training
SegFix: Model-Agnostic Boundary Refinement for Segmentation
Augmented Geometric Distillation for Data-Free Incremental Person ReID
Intermediate Prototype Mining Transformer for Few-Shot Semantic Segmentation
Open-world Semantic Segmentation via Contrasting and Clustering Vision-Language
Segment Anything in High Quality
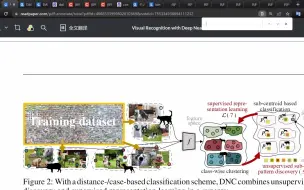
Visual Recognition with Deep Nearest Centroids
k-means mask transformer
Part-based Pseudo Label Refinement for Unsupervised Person Re-identification
SAM Fails to Segment Anything? – SAM-Adapter: Adapting SAM in Underperformed Sce
openVocabulary semantic segmentation with mask-adapted clip
advhat+adversarial-yolo+gen-ap+adv-glasses+步态攻击 攻击方法的比较
HorNet: Efficient High-Order Spatial Interactions with Recursive Gated Convoluti
跟随大佬实践的一站式响应网站
Learning self-consistency for deepfake detect
Images Speak in Images: A Generalist Painter for In-Context Visual Learning
Per-Pixel Classification is Not All You Need for Semantic Segmentation