V
主页
京东 11.11 红包
开源Mistral-7B LORA微调 增强中文能力演示
发布人
开源Mistral-7B LORA微调 增强中文能力演示
打开封面
下载高清视频
观看高清视频
视频下载器
中文ChatGLM-6B预训练模型 5.2万提示指令微调演示
几百次大模型LoRA和QLoRA 微调实践的经验分享
Text2SQL Llama 7B模型微调DuckDB-NSQL-7B #小工蚁
统一Embedding模型增强 大语言模型能力 #小工蚁
LoRA是什么你了解吗? 优化Stable Diffusion的微调
开源Mistral 7B开箱测试 性能炸裂,推理比Qwen-7B快4倍 #小工蚁
大模型微调训练实践 准确度10%提升至90%
微调大语言模型如何自动生成 训练数据以及优化技巧
上海人工智能实验室InternLM-7B模型升级,增强Tools使用能力 #小工蚁
StarCoder开源代码AI模型微调成编程助手
智源公开大模型SFT训练数据集微调后性能达到和超过GPT4
什么场景下大模型需要微调?#小工蚁
AutoLabel:自动标注,比人快100倍,准确度和人一样!#小工蚁 #大语言模型
基于LLaMA-2微调中文大模型 千元预算,效果媲美主流大模型
华为盘古Pangu-Code2:如何微调出接近GPT4水平的性能?
WebGLM:高效网络增强型问答系统,清华开源模型
腾讯开源LlaMA Pro增强LLM性能 新方法,打造行业模型 #小工蚁
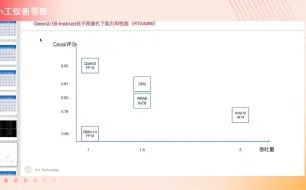
Qwen2-7B-Instruct不同量化方法准确度和性能比较
DeepSeek V2开源大模型为什么可以节省90% 以上KV Cache?
国产首个开源MoE大模型DeepSeekMoE 16B #小工蚁
比较3种开源大模型Roberta Llama2,Mistrial微调性能
ChatGLM2如何进行模型微调演示 #小工蚁 #chatglm2
开源类似ChatGPT模型如何微调?
演示xllm-stream镜像如何可视化微调模型?#小工蚁
Jamba开源模型性能超越 Mixtral8*7B 采用最先进混合架构
如何消除大模型幻觉? 提高准确率 LoRA+MoE
PDF文档文字、表格混排自动识别,增强RAG应用准确度 #小工蚁
清华开源ChatGLM 2代模型演示 轻松实现平滑升级
Flowise重磅更新,零代码实现多文件检索增强生成和AI智能体!支持JinaAI嵌入模型+ministral 8b模型轻松打造RAG知识库!打造专属AI助手
LLM如何接入到个人微信? 演示群聊中AI自动回复
LLaMA-Omni开源语言对话大模型,超低延时 #小工蚁
使用RTX4090+GaLore算法 全参微调Yi-6B大模型
抱抱脸开源小模型SmolLM和训练数据集 #小工蚁
Docker容器中运行大语言模型 推理加速,使用更简便
微调开源模型具备Function Call讲解和演示 #小工蚁
企业如何构建自己的ChatGPT 中文LLM大模型和微调方法推荐
超越GPT3.5开源模型Mixtral 真来了,可免费商用
清华智谱开源生成视频大模型CogVideo
Qwen2.5-Coder写代码大模型技术报告解读 #小工蚁
复杂任务需要模型微调选择 GPT-3.5还是Llama2开源模型?