V
主页
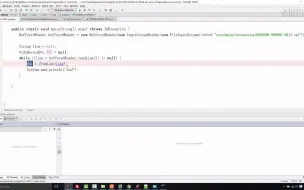
2-7HBase内存规划案例
发布人
打开封面
下载高清视频
观看高清视频
视频下载器
3-7基本类型及其操作
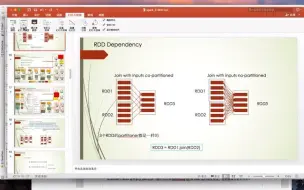
3-7RangePartitioner的原理
2-7理解Spark分布式内存计算的含义
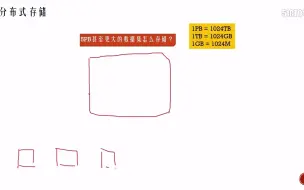
1-7分布式存储的原理
1-13HBase技术架构
6-7虚拟机关闭防火墙
1-2引出主角HBase
3-7RangePartitioner的原理
02_关于内存那点事
07_测基本类型的变量在内存中占的字节数
1-7HA配置
4-7单元测试、集成测试以及验证
4-7RowKey的过滤
6-4Spark使用bulkput将数据写入到HBase中
4-7本地(Local)函数
3-7grep命令
7-4HFile导入到HBase并验证
3-2pre-split(设计HBase表时必须考虑的点)
6-5Spark使用bulkput将数据写入到HBase中优化
4-1Java客户端增删改Hbase表
3-7实现并运行第一个MapReduce job
4-2NCDC数据字段的详解
10_sscanf高级用法
1-8Java客户端put数据到HBase表
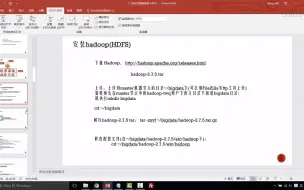
1-9HDFS的安装(一)
04_指针的定义方法
6-1Spark在driver端和executor端读写Hbase
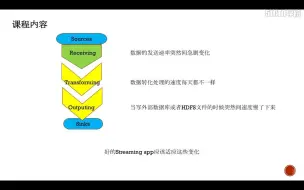
3-1课程内容
1-1课程内容
02_数组的分类
02_include
4-3NCDC数据的预处理
1-27Federation配置
02_strcpy
2-1课程内容
4-5Flume的基本架构和基本术语
4-1NCDC数据源的获取
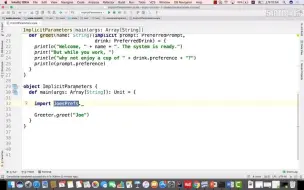
6-9隐式解析机制
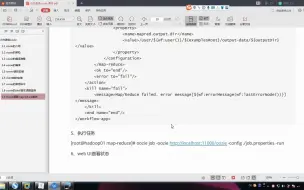
好程序员大数据教程:10 oozie的map-reduce案例
3-23CombineTextInputFormat讲解