V
主页
3-18实践:RDD的pipe api的使用
发布人
打开封面
下载高清视频
观看高清视频
视频下载器
3-17RDD分层采样api(sampleByKey等)
2-18zk使用之Master选举实战
1-18HDFS各组件作用
3-23ShuffleRDD的原理详解
7-24DataFrame中Untyped API讲解
1-12transform API
7-32RDDsDataFramesDatasets各自使用场景
7-26Dataset typed API
3-25实践:combineBykey实战以及使用过程中需要注意的点
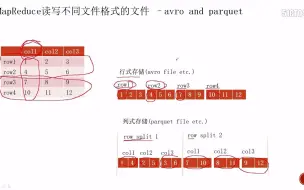
3-18avro文件和parquet文件的讲解(很重要)
7-8实战:schema api的用处
3-1再次理解RDD概念
18-压缩数据、以不同压缩方法注入URL、Hadoop配置Snappy压缩
20200320_100618混合赋值和字面量
3-27cogroup api的感官认识
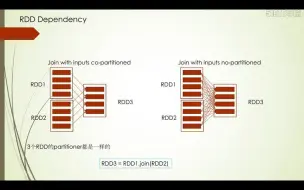
3-29join等api的原理实现
3-15MapPartitionsRDD的原理代码详解
6-4Spark使用bulkput将数据写入到HBase中
2-17zk使用之分布式锁实战
3-6实战:对RDD合理分区能提高性能
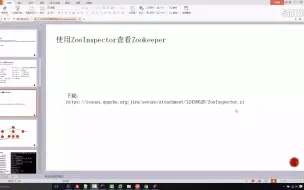
2-5使用ZooInspector操作zk
2-9列表Lists的使用
2-10元组Tuples的使用
2-16zk使用之配置管理实战
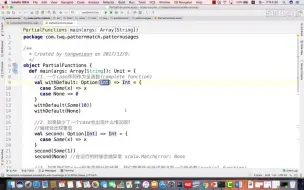
5-18模式在偏函数中的使用
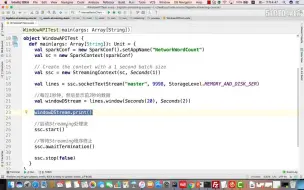
1-13window(窗口) API
7-2浅尝spark SQL的API
6-2隐式系统使用场景
2-7使用foreach和for进行迭代
3-34intersection的使用及其原理.mkv
2-9Spark SQL组件解决的问题及其特点一
5-8task调度的延迟调度讲解一
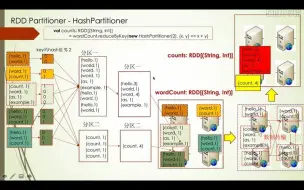
3-5HashPartitioner原理
1课程内容
3-35cartesian笛卡尔积的使用及其原理.mkv
20_指针作为函数的返回值
6-2修改主机名
03_数组的定义
10_冒泡法排序
2-3Spark分布式计算流程中的几个疑问点