V
主页
Talk|香港中文大学高瑞元:MagicDrive - 基于3D几何控制的自动驾驶街景数据生成
发布人
本片为将门-TechBeat技术社区第565期线上分享Talk! 有问题?想提问?快来在的https://datayi.cn/w/noqbYOd9【交流区】留言!香港中文大学博士生 高瑞元会亲自下场回复哦! 更多Talk视频,尽在将门TechBeat技术社区>> www.techbeat.net
打开封面
下载高清视频
观看高清视频
视频下载器
FluxMusic: 基于FLUX的高效文本到音乐生成系统
Talk | 卡耐基梅隆大学何泰然:安全、敏捷、能泛化的基于强化学习的机器人控制
Talk|清华大学诸子钰:面向具身智能的通用3D视觉语言理解
AI已经离谱到这种状态了?
人类记忆是否被‘清空过’,AI人工智能认为1913年是人类文明的巅峰
【深度生成模型 CS236 2023】斯坦福—中英字幕
FSD V12 恐怖的感知能力
注意:内容系AI生成,请仔细辨别~
FSD 纯视觉大暴雨照样随便高速随便开。请问某激光雷达的车为什么这种雨反而要退出呢?#特斯拉 #自动驾驶 #人工智能 #特斯拉自动驾驶 #FSDV12
讲座 | 三维室内场景纹理图生成——慕尼黑工业大学视觉实验室24届博士陈振宇
Talk | CoRL 2023 Oral 上海交通大学迮炎杰:通用机器人操作的视觉表征
研一在读,代码完全不会,如何入门深度学习?
【神经网络杀疯了!】登上了nature神坛!迎来人工智能新的里程碑:被证明具有泛化能力,能像人类一样思考!
Talk | UCSB博士生赵宣栋:生成式AI时代的水印技术
Talk | 香港中文大学(深圳)颜旭:利用跨模态知识蒸馏增强点云的表征学习
Talk | 香港中文大学在读博士生陈玉康:VoxelNeXt实现全稀疏3D检测跟踪,结合SAM加速3D标注
Talk|UW-Madison蔡沐:图像可编码为任意数量Token,俄罗斯套娃式多模态大模型
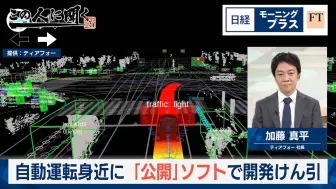
日本的自动驾驶
上海 AI Lab开源力作!DriveArena: 首个基于生成模型的自动驾驶闭环仿真平台
Talk|香港中文大学(深圳)张雪遥:音频生成开源工具包Amphion的歌声转换指南
“害怕是源于不了解”- 中通快递自动驾驶司机说
MeshFormer: High-Quality Mesh Generation with 3D-Guided Reconstruction Model
Talk | AAAI'23 杰出学生论文 - 北京大学甘雨露:基于视觉提示的连续环境变化下模型自适应方法
Talk |新加坡国立大学胡志元:Uncertainty of Thoughts:大型语言模型的信息搜寻与决策
Talk精华版 | 香港中文大学博士赵恒爽:探索自注意力机制在图像识别中的应用
Talk|香港中文大学赖昕:LISA - 推理分割新范式
搞深度学习因数据不够质量不好导致模型性能差怎么办?30分钟用一个视频全都给你解决!-神经网络/图像处理/计算机视觉
Talk | 浙江大学特聘研究员廖依伊:面向自动驾驶仿真平台的神经渲染
Talk | 斯坦福大学徐霄萌:Dynamics-Guided Diffusion Model:用于机械手设计的动力学指导扩散模型
这位印度小哥真的有一套!数据科学的王!终于有人提到他啦!
Talk | 新加坡国立大学赵轩磊:Pyramid Attention Broadcast:通向视频模型的实时生成
Talk | 清华大学在读博士生李一鸣:后门攻击简介
Talk|东京大学楚选耕:仅需单图,秒级重建可驱动3D头像
Talk|清华大学袁天远:PreSight - 利用NeRF先验帮助自动驾驶场景在线感知
【自动驾驶技术】花18000大价钱买的无人驾驶课程,从入门到提升的自动驾驶算法——感知实战、视觉定位、预测系统、路径规划、控制理论、强化学习
华为AI顶会新工作!半监督3D分割的贝叶斯自训练!中稿ECCV 2024!
Talk|卡内基梅隆大学李博文:适用于机器人的可泛化的目标感知
仅用60行Numpy代码就实现了GPT,连OpenAI首席科学家Karpathy都点赞了!
Talk节选版 | ICLR'21 Oral 一作孔之丰: DiffWave, 一种基于降噪扩散概率模型的普适音频生成模型
Talk | 香港中文大学张懿元:由MetaTransformer探索统一的多模态学习