V
主页
爬虫- 37-下载图片
发布人
打开封面
下载高清视频
观看高清视频
视频下载器
爬虫- 78-代理ip设置
爬虫- 96-selenium结合scrapy
爬虫- 01-html
爬虫- 82-源码形式获取51job数据
爬虫- 91-生成器
爬虫- 52-豆瓣电影排行数据
爬虫- 86-12306抢票思路
爬虫- 15-背景设置
爬虫- 05-服务器处理表单post提交
【2024年数据分析】10小时学会数据分析、挖掘、清洗、可视化从入门到项目实战(完整版)学会可做项目
爬虫- 67-多进程数据共享的方法
爬虫- 18-首页效果
爬虫- 89-scrapy基本流程
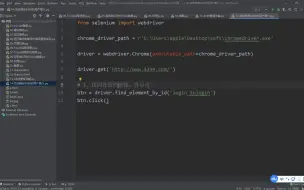
爬虫- 72-selenium的基本使用
爬虫- 58-51job数据获取
爬虫- 10--css导入方式和优先级
爬虫- 85-4399手动登录.mp4
爬虫- 25-数组方法
爬虫- 42-复习
爬虫- 95-第一个post请求
爬虫- 40-代理和处理不受信任网站
爬虫- 98-scrapy-redis
爬虫- 20-基本语法
爬虫- 12-css浮动
爬虫- 03-html3,socket
爬虫- 28-字符串练习
爬虫- 54-xpath的基本语法
爬虫- 36-ajax加载数据
爬虫- 97-规则爬虫
爬虫- 43-cookie的原理
爬虫- 68-多线程数据共享,加锁解决错误错乱
爬虫- 90-通过 item封装数据,在pipeline中保存数据
爬虫- 08-div和span元素
爬虫- 11-css的选择器
爬虫- 09-pre标签
爬虫- 02-html2
爬虫- 16-盒子模型
爬虫- 33-js事件
爬虫- 60-bs4用法
爬虫- 32-找元素对象