V
主页
京东 11.11 红包
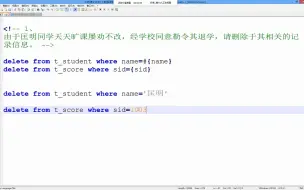
kafka10_-偏移量的生成问题01
发布人
打开封面
下载高清视频
观看高清视频
视频下载器
【七天做完大数据毕设】基于Hadoop、Hive和Spark的当当网图书可视化分析系统 第1小节 项目介绍
【七天做完大数据毕设】基于Hadoop、Hive和Spark的当当网图书可视化分析系统 第3小节 数据存储
42-spark sql-数据写入hive
【七天做完大数据毕设】基于Hadoop、Hive和Spark的当当网图书可视化分析系统 第6小节 数据同步
【七天做完大数据毕设】基于Hadoop、Hive和Spark的当当网图书可视化分析系统 第2小节 数据采集
30-spark streaming-从kafka消费数据
【七天做完大数据毕设】基于Hadoop、Hive和Spark的豆瓣电影可视化分析系统 第1小节 项目介绍
kafka09_-消息存储格式01
Hadoop
28-spark streaming-原理介绍
基于HDFS的百度云盘-104-新独立访客的思路
kafka26_-生产者消费者的配置参数详解
Hadoop理论基础-64_idea搭建hadoop集群.mp4
sqoop07-allowinsert模式 和updateonly模式
scala23_-子类与父类构造器的执行顺序问题-lazy
kafka08_-存储机制02
zookeeper01-Hadoop HA-01
14-spark-on yarn-cluster模式01
【原创大数据毕设】基于大数据汽车数据分析系统(Hadoop Hive MySQL Azkaban Springboot Echarts)爬虫,大数据毕业设计
flume01_使用场景
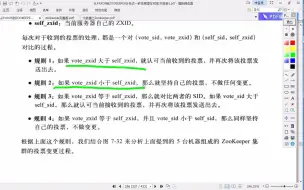
zookeeper11-运行期间leader选举的四个规则
Hive_08_sql案例01_hive的删除操作
zookeeper07-leader的选举01
Hive_36_hive-分桶
基于HDFS的百度云盘-103-统计回话次数思路
scala47_-泛型类与泛型函数及其上界约束与下届约束
【python大数据毕设实战】 基于python的美食推荐及分析系统 包括推荐算法、爬虫数据分析、机器学习、Web应用、大数据
hbase25_-rowkey的设计原则
hbase13_-minjor与major合并的区别
整合flume、hive、sqoop的百度云盘项目-01--数据采集-火车头采集器
15-spark--collect算子
02-spark-countbykey
基于HDFS的百度云盘-95-SpringMVC整合HDFS实现云盘的文件上传
基于HDFS的百度云盘-105-echarts报表工具
scala01_基础语法-idea安装插件
ambari安装-71-ambari安装介绍01
kafka25_-低级消费者-异步同步提交偏移量-再均衡监听器
scala10_数组
23-spark-RDD、DataFrame和DataSet的区别
2024吃透消息队列系列教程,一周刷完消息中间件RabbitMQ、RocketMQ、kafka,让你面试少走99%的弯路!【存下吧,附100W字面试宝典】