V
主页
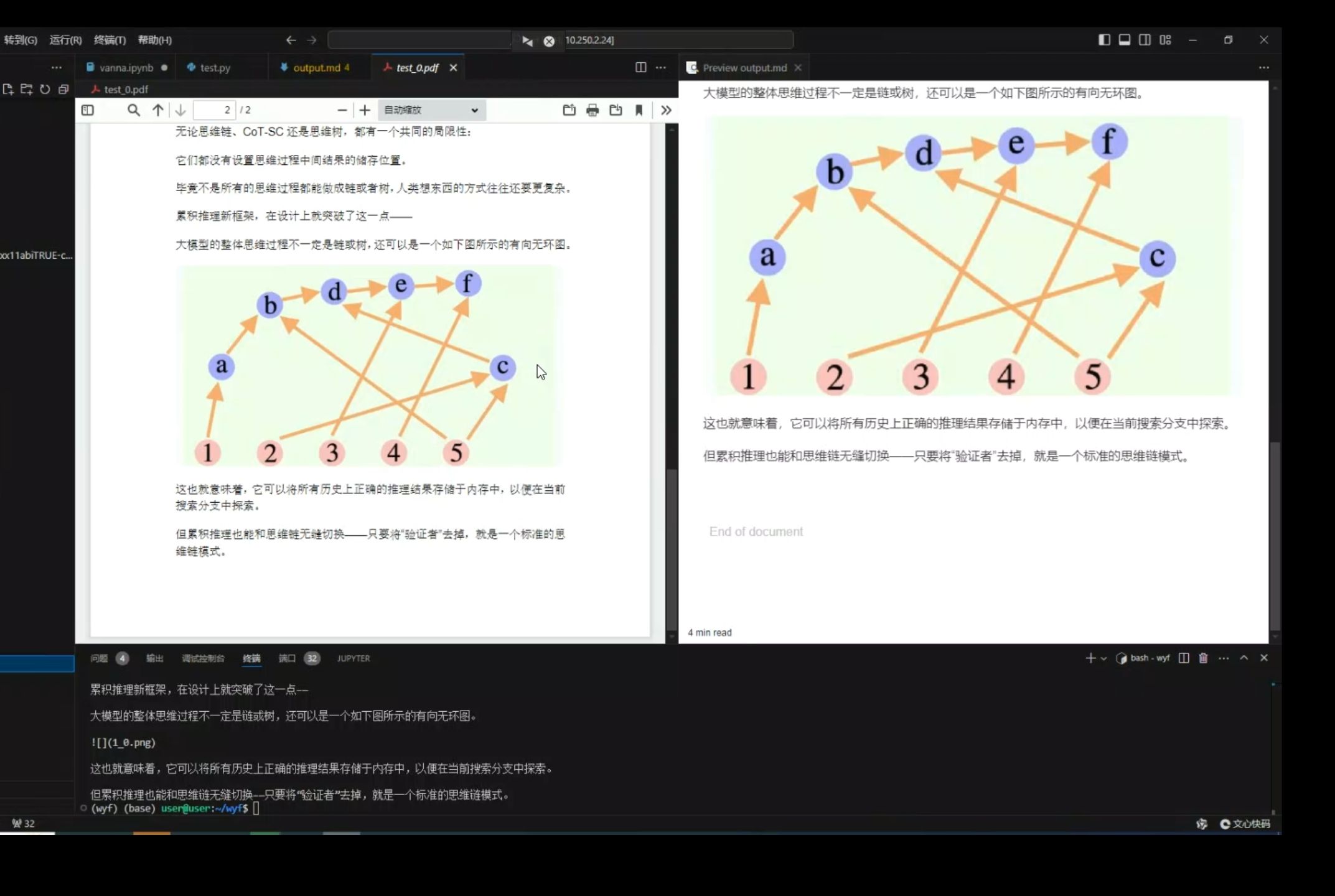
Qwen2-VL-7B实现精准pdf转markdown,从原理、代码实现、存在问题以及优化方向全流程讲解
发布人
国产多模态大模型之光Qwen2-VL-7B结合gptpdf实现高效的pdf文档转markdown,原理、代码、优化全流程讲解,通俗易懂
打开封面
下载高清视频
观看高清视频
视频下载器
多模态RAG:结合 Qwen-2-VL和ColPali实现pdf文献图表检索 突破传统rag图表文献识别挑战
12GB版3060本地运行(Int8量化)Qwen2-VL-7B-Instruct 推理速度
基于AI的PDF转 Markdown,开源免费,高精度还原,用在AI知识库系统里面,能有效优化RAG,提高AI回复质量
超越GPT-4o视觉能力?本地部署Qwen2-VL多模态视觉大模型!超越人类的视觉理解能力,精准识别X光片判断骨折、CT扫描检测癌症,还能识别手写体汉字与英文!
PDF转HTML格式,专精于OCR识别的多模态大模型,适配多场景多功能。从原理到效果实测,带你一步一步解析。
gptpdf:使用GPT-4o解析 PDF 为 markdown,可完美地解析排版、数学公式、表格、图片、图表等,每页解析平均价格不到1毛钱
Qwen2大模型保姆级部署教程,快速上手最强国产大模型
论文速读30:Qwen2-VL
GraphRAG太烧钱?Qwen2-7b本地部署GraphRAG,无需Ollama,从环境搭建到报错解决全流程
【直播录屏】Qwen2大模型微调
版面分析模型结合Qwen2-VL-7B,大幅提升gptpdf解析效果,代码实现更简洁、更高效
4060Ti 16G显卡安装Qwen2-VL多模态模型识别视频/图片效果及安装注意事项
如何轻松部署Qwen2:本地与云端部署指南! Qwen2、Llama3、GPT4o,模型深度对比。
全面超越GraphRAG,速度更快,效果更好,落地部署更方便。从原理、本地Qwen2.5-3B模型部署到源码解读,带你全流程解析LightRAG
提升AI知识库效果,从PDF转Markdown开始
【强烈推荐】PDF转换.md!AI识别超高准确率 本地部署教程MinerU
今日Github最佳开源项目,MinerU一站式开源高质量数据提取,PDF文档和网页电子书提取,转换为Markdown格式,家人们,赶快去了解一下吧!
【我 们 上 央 视 了!】Hugging Face 抱抱脸呼吁人工智能开源
RAG增效SQL语句生成,开启大模型做数据查询新思路,本地Qwen2-7b模型也能又快又准
【论文导读】Qwen2-VL
本地安装Qwen2-VL 2B-Instruct 效果最好的视觉语言模型
吹爆!这绝对是南京大学最出名的LLAMA3教程了没有之一,llama3原理代码精讲与微调量化部署实战,通俗易懂太适合小白了!人工智能|机器学习|深度学习
最新多模态大模型QWEN2-VL详细教程-环境配置、数据集构建、模型微调、训练流程、效果展示
Qwen2-VL-7B强大的多模态视觉模型在ComfyUI中的实现,视频&图片&文本处理
阿里豁出去了!开源了通义千问全尺寸模型(本地部署Qwen2-VL教程)
0.5B小模型将原始HTML完美转换为干净的Markdown,或许专用场景的小模型才是未来主流
本地部署 通义千问 Qwen2 7B
多模态大模型QWen2-VL 72B在安防任务火焰识别的表现
超越GPT-4o,阿里新开源Qwen2-VL视觉语言模型
RAG实战系列,如何针对word文档中的表格进行问答,解决跨页表格问题
5分钟学会微调大模型Qwen2
RAG实战系列(医疗知识问答),从零开始实现多路召回检索,带你了解检索流程和算法原理
Qwen2-Vl本地整合包,AI视频理解,AI图片理解,千问2视觉模型测试,基于视频的问答、对话、内容创作等方式理解20分钟以上的视频
在Qwen2.5基础上训练的最强表格模型诞生,适配excel、csv和数据库等结构化数据,查询、分析、可视化、建模无压力
开源工具MinerU助力复杂PDF高效解析提取
【研1基本功 JAX加速框架】pytorch太慢,我偶尔选jax~
Qwen2-7B-微调-训练-评估
本地部署Molmo-7B多模态大模型媲美Llama3.2-90B!全方位测评:图像识别、视频分析,打造多模态视觉AI助手!轻松实现监控视频快速找人
Marker:你的PDF解析大杀器。让LLM更懂你的数据。
Qwen2为何“高分低能”?实测中表现还不如Qwen1.5!