V
主页
京东 11.11 红包
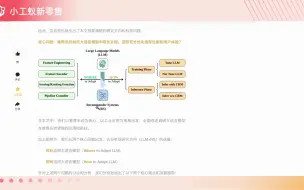
vAttention大模型高效推理动态内存管理新方法
发布人
vAttention大模型高效推理动态内存管理新方法
打开封面
下载高清视频
观看高清视频
视频下载器
大模型推理指令缓存功能 推理性能提升30% #小工蚁
ggml开源大模型推理轻量框架 支持手机推理大模型
BCE Embedding开源大模型 RAG应用准确度提升关键
LightRAG一种简单高效的RAG新方法 #小工蚁
AutoLabel:自动标注,比人快100倍,准确度和人一样!#小工蚁 #大语言模型
使用Triton内核加速Llama3-70B FP8推理 #小工蚁
NL2SQL大模型生成SQL调研报告
Embedding模型8bit量化推理 成本下降4倍,准确度下降0.7%
Prefix Caching原理和对大模型推理加速影响 #小工蚁
打造智能客服:LLM和本地 知识库的完美协同原理
了解大语言模型技术细节(2/3)高效微调方法
谷歌开源时间序列大模型 直接使用不需要训练 #小工蚁
近期开源VLM大模型介绍 #小工蚁
用GPTQ算法量化大型模型 大幅减少GPU使用并提高准确率
清华智谱开源视觉大模型 CogVLM,可免费商用
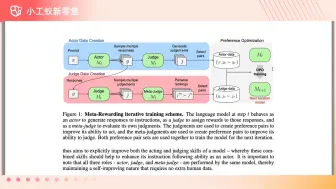
大模型自我改善对齐,无需人类反馈
DeepSeek V2开源大模型为什么可以节省90% 以上KV Cache?
M3E中文文本嵌入模型:替代OpenAI text-embedding-ada-002的最佳选择
大语言模型的技术细节 分布式训练和推理(3/3)
如何消除大模型幻觉? 提高准确率 LoRA+MoE
人工智能在制造行业应用场景(1/2)
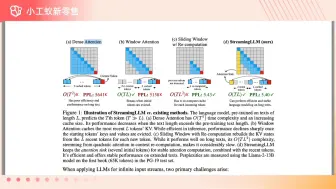
无限上下文大模型推理加速StreamingLLM #小工蚁
几百次大模型LoRA和QLoRA 微调实践的经验分享
了解大语言模型技术细节(1/3)
训练大语言模型LLM 如何定义自己训练数据集?#小工蚁
LLM如何接入到个人微信? 演示群聊中AI自动回复
将新鲜知识注入大型语言模型:只需一个命令!#小工蚁 #rome
StreamingLLM算法让推理速度 提升22倍,支持400万Token输出
小工蚁开源大模型解决方案 快速部署,轻松满足定制需求
LLM大模型应用场景2:Text2SQL #小工蚁
DSPy提示工程自动优化框架 #小工蚁
大模型提示工程技术 调研报告(上)
百川2大语言模型推理加速 对比实验测试,性能提升100倍
用LLM从文本中自动提取数据 生成表格的新算法效率提升110倍
LLM推理过程中自动缓存KV Cache功能 #小工蚁
算子优化MoE模型推理加速4倍
如何提高垂直领域RAG准确率? #小工蚁
当推荐系统遇到大语言模型会有什么化学反应?#小工蚁 #推荐引擎 #LLM
清华发布SmartMoE一种高效训练专家模型网络算法 #小工蚁 #清华 #MoE
从 SAM 到 FastSAM:中科院团队成功实现通用视觉模型速度革命