V
主页
京东 11.11 红包
Spark中的广播变量是什么?
发布人
Spark中的广播变量(Broadcast Variables)是一种用于在分布式计算中共享大型只读数据集的机制。广播变量在 Spark 作业中广播一个只读变量到每个工作节点,以便每个节点可以访问该变量而无需在每个任务中复制该数据。这可以有效减少数据传输和内存开销,提高性能。广播变量通常在以下情况下非常有用: 1、减少数据传输开销:当需要在Spark作业的每个任务中使用相同的只读数据集时,广播变量可以减少数据传输开销。而不广播变量的情况下,该数据集会被多次复制到每个任务,导致不必要的网络传输和内存占用。 2、提高性能:广播变量可以显著提高性能,尤其是在涉及大型只读数据集的情况下。它减少了数据的冗余复制和内存占用,使任务能够更快地执行。 3、内存管理:通过使用广播变量,Spark可以更好地管理内存,避免数据的多次复制,从而减少内存压力。 4、大型配置数据:广播变量通常用于传递大型配置数据、机器学习模型参数、参考数据等。 广播变量在许多情况下都非常有用,尤其是当您需要在Spark任务中访问大型只读数据集时,它可以显著提高性能和资源利用率。
打开封面
下载高清视频
观看高清视频
视频下载器
Spark中的Shuffle是什么?
Spark的数据处理模型是什么?
Spark的核心组件是什么?
什么是Spark GraphX?
Spark中的数据缓存和数据持久化机制
什么是Spark的调度器,它的调度模式有哪些?
Spark的内存管理和调优机制
Flink CDC 是什么?
Flink CDC 的实现原理是什么?
什么是HBase?它与传统的关系型数据库有什么不同?
Spark Streaming 原理
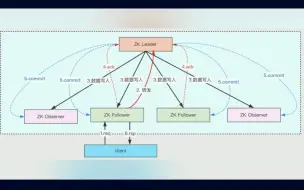
什么是 ZooKeeper?它的作用是什么?
Flink 的基本概念是什么?
什么是 Ingress?
数据湖与大数据?
2024Spark-9-Spark安装与编译
大数据 HDFS 工作原理
什么是大数据
【七天做完大数据毕设】基于Hadoop、Hive和Spark的当当网图书可视化分析系统 第2小节 数据采集
【七天做完大数据毕设】基于Hadoop、Hive和Spark的当当网图书可视化分析系统 第1小节 项目介绍
数据湖与数据仓库的比较?
数据湖的未来趋势?
k8s iptable 和 ipvs 模式的区别
Flink CDC 的应用场景是什么?
Prometheus Grafana 可视化模块?
【原创大数据毕设】基于大数据汽车数据分析系统(Hadoop Hive MySQL Azkaban Springboot Echarts)爬虫,大数据毕业设计
什么叫大数据,有什么用途?
MapReduce 五个阶段说明
k8s 普通日志和events日志区别?
Flink 的事件时间和处理时间是什么?
大数据求偶bfb
Flink 窗口是什么?
数据湖 Hudi 介绍
MapReduce 的应用场景是什么?
为什么选择数据湖?
什么是 etcd?
Flink CDC 如何捕获数据库中的数据变化?
Flink 的容错机制是什么?
Spark,Flink与Hudi整合使用
什么是数据思维