V
主页
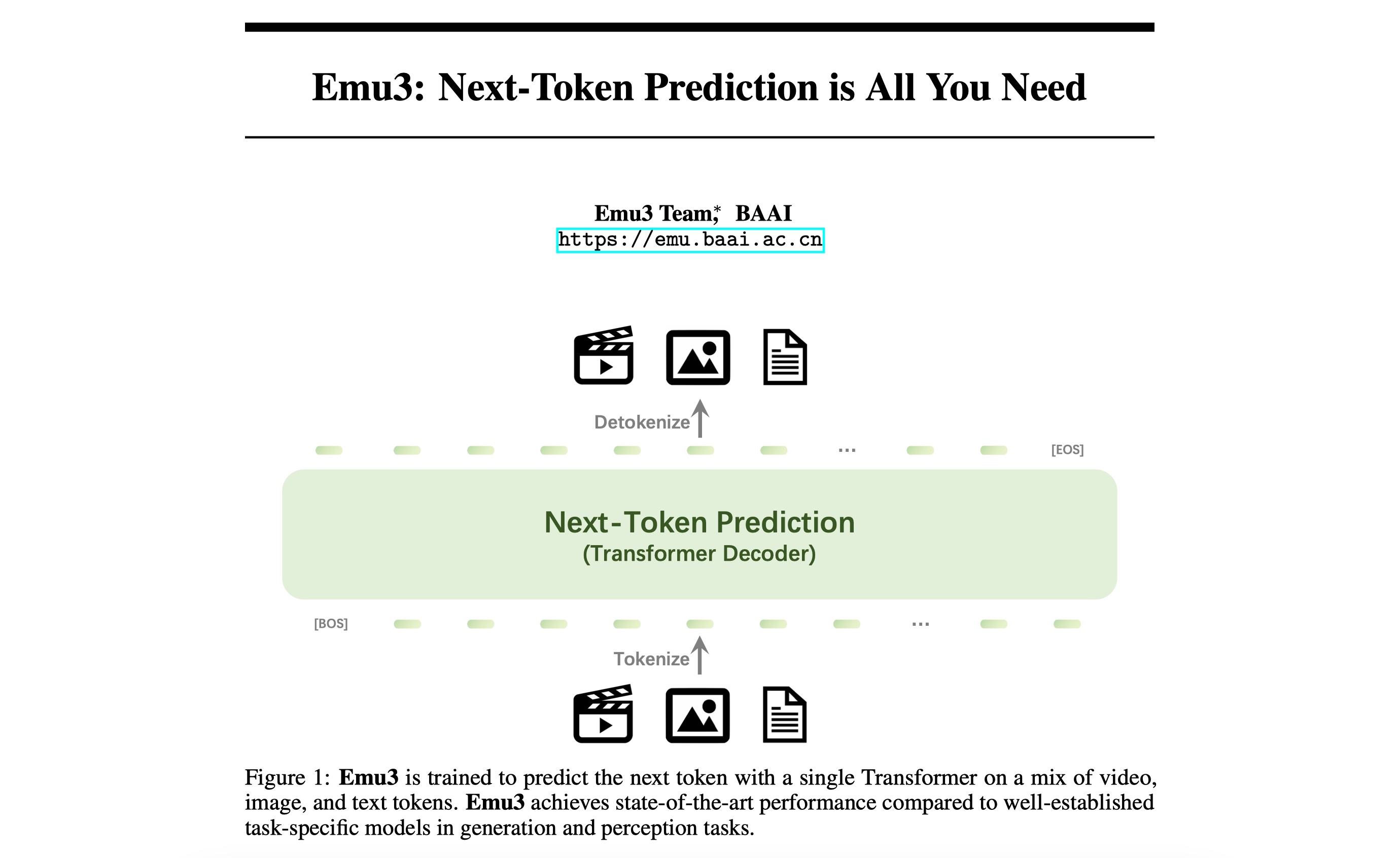
Emu3:统一理解和生成的多模态大模型
发布人
arxiv:https://arxiv.org/abs/2409.18869 GitHub:https://github.com/baaivision/Emu3
打开封面
下载高清视频
观看高清视频
视频下载器
VILA-U:端到端的统一理解和生成任务的多模态大模型
Qwen2-VL:支持任意精度图片以及视频输入的开源大模型系列
Fluid:使用连续token表示,随机顺序生成的自回归文生图模型
Janus:基于分离视觉编码器的统一理解与生成的多模态大模型
LLaMA-omni:低延时的语言交互多模态大模型
【NeurIPS2024 Oral】VAR:使用next scale prediction,基于自回归架构的图片生成模型
LLaVA-MoD:基于知识蒸馏的小多模态大模型
ChartMoE:使用MoE adapter的Chart理解多模态大模型
强到离谱!一年轻松发6篇综述SCI!B站最全SCI论文写作指导教程,研究生SCI论文从写作到发表全过程精讲,太适合小白了!人工智能|SCI|论文写作
SHOW-o:统一理解和生成任务的transformer
LLaMA3.2:LLaMA3.2大模型系列
transfusion:统一transformer和diffusion框架的多模态大模型
RAR:一个基于token shuffling的提升自回归架构图片生成模型表现的策略
【共享LLM前沿】假如我从11月1号开始学大模型!9小时学会搭建对话机器人办公助手、大模型预训练微调、四大多模态大模型!
mini-Gemini:支持高精度图片输入的多模态大模型
NVLM:融合LLaVA和Flamingo架构的多模态大模型系列
LongLLaVA:基于Jamba的多图理解多模态大模型
AVG-LLaVA:自适应尺度视觉特征选择的多模态大模型
mono-internvl:一体化的多模态大模型
【LLM前沿】6小时精讲四大多模态大模型CLIP BLIP VIT MLLM及对话机器人办公助手!绝对的通俗易懂的大模型应用教程!
Research Track 7:多模态大模型最新的一些论文
Open-MAGVIT2基于Lookup-free Quantization的开源图片生成模型
agent Q: 超强网页交互agent
OLMoE:基于MoE的全开源大模型
Research Track 4: 多模态大模型最新的一些论文
【导师散养不教】研究生1个月如何拿下SCI三区一作?基本套路+实操演示,手把手带你轻松搞定SCI论文!(SCI论文/SCI论文写作/人工智能)
Ferret-UI 2:拥有跨平台UI理解的多模态大模型
CogVLM2:智谱AI新一代多模态大模型系列
花了我6800,大模型算法工程师稳了!构建专属大模型的大模型入门到就业教程,人工智能、神经网络、transformer、视觉模型、NLP、提示工程
mini-omni:实时可交互语音大模型
GPT五步提问:一天写完一篇综述小论文
mPLUG-Owl3 多图理解多模态大模型
英伟达发布MM-Embed:融合文本和图像的跨模态信息检索新模型
Aria:基于MoE架构的原生多模态大模型
UnifiedMLLM:多任务多模态大模型
Cambrian-1:以视觉为中心,基于多个vision encoder的多模态大模型
Research Track 8:比较关注的一些论文
从入门到提示词工程师:全网最通俗易懂Prompt-Learning提示词学习教程!草履虫都学的会!
【共享LLM前沿】通俗易懂搞懂四大多模态大模型CLIP BLIP VIT MLLM及对话机器人办公助手!大模型预训练微调
Research Track 1:多模态大模型最新的一些论文