V
主页
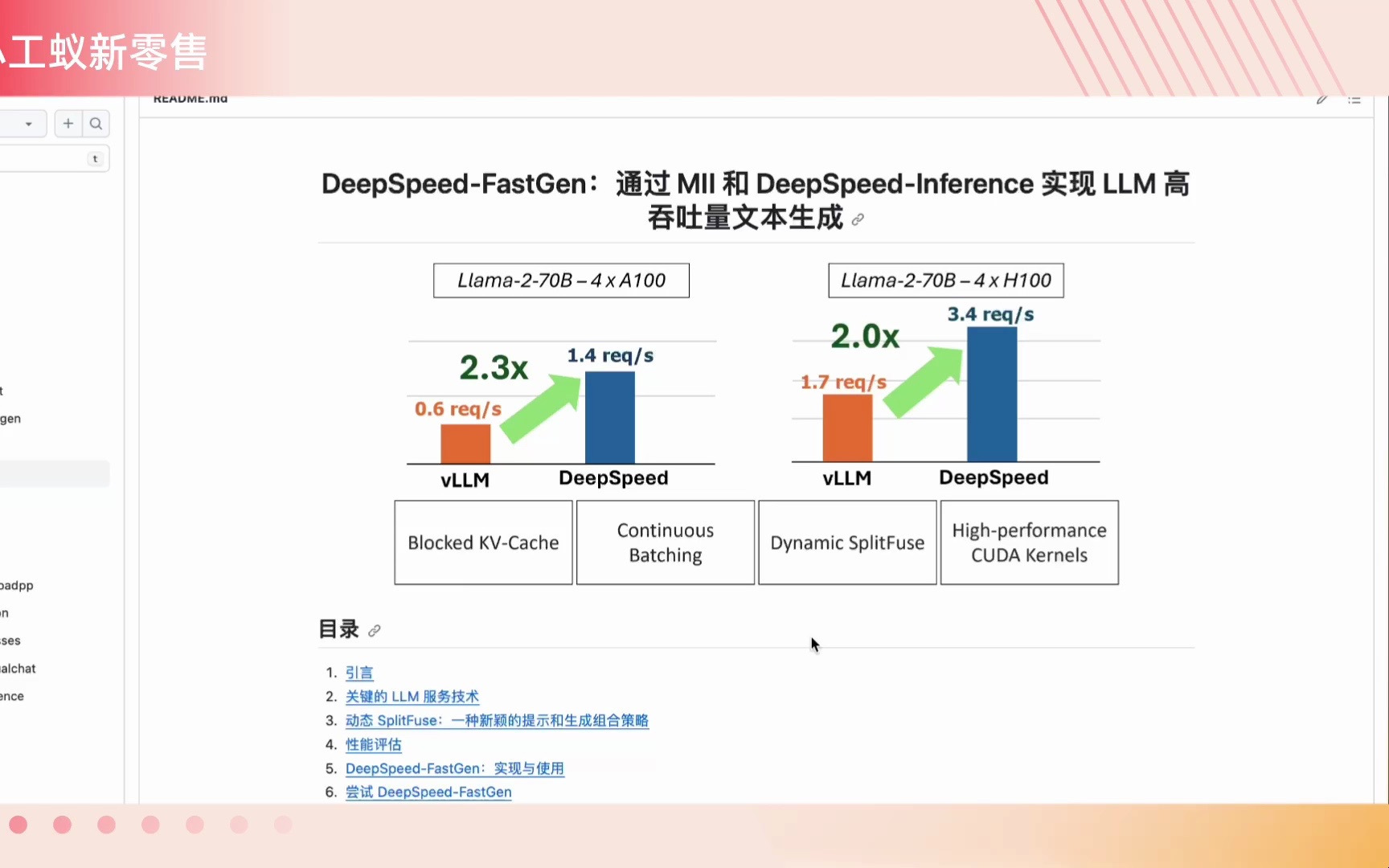
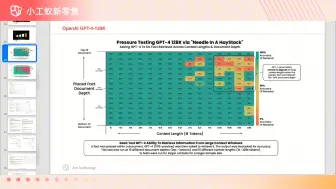
DeepSpeed-FastGen比vLLM推理性能快2倍,SplitFuse策略 #小工蚁
发布人
DeepSpeed-FastGen比vLLM推理性能快2倍,SplitFuse策略 #小工蚁
打开封面
下载高清视频
观看高清视频
视频下载器
LightLLM轻量级高性能推理框架 和vLLM哪个更强?
llama.cpp大神实现投机采样,让大模型推理性能直接翻倍 #小工蚁
如何让清华ChatGLM2-6b模型推理性能提升20倍? #小工蚁 #chatglm2
AutoLabel:自动标注,比人快100倍,准确度和人一样!#小工蚁 #大语言模型
谷歌发现RAG缩放定律 释放LLM长上下文潜力 提升RAG准确率 #小工蚁
FinGPT: 轻量级适应在金融领域高效LLM解决方案 #小工蚁 #chatglm #chatgpt
将LLaMA3上下文长度从8K扩展 到超过100万
Qwen2.5-Coder写代码大模型技术报告解读 #小工蚁
LangGraph Autogen CrewAI 哪个Agent框架更好?#小工蚁
大模型推理性能优化策略 #小工蚁
Qwen1.5系列6个模型如何选择? AWQ还是GPTQ?#小工蚁
LLaMA3.1-8B性能评测 如何运行性能最优?#小工蚁
腾讯开源LlaMA Pro增强LLM性能 新方法,打造行业模型 #小工蚁
如何将LLM输出文本转为结构化数据? #小工蚁 #langchain
Text2SQL Llama 7B模型微调DuckDB-NSQL-7B #小工蚁
近期开源VLM大模型介绍 #小工蚁
Meta开源Llama2模型申请 下载和使用演示 #小工蚁 #llama2
ChatGLM2如何进行模型微调演示 #小工蚁 #chatglm2
知识图谱如何提升大模型智能问答应用准确度 #小工蚁 #知识图谱
DeepSeek V2开源大模型为什么可以节省90% 以上KV Cache?
QAnything网易开源RAG应用 支持多种文件格式 #小工蚁
清华发布CodeGeeX2生成代码大模型,它性能究竟如何? #小工蚁 #清华 #codegeex
Ollama在Mac上运行大语言模型 #小工蚁
微软开源DeepSpeed-MoE训练更大更复杂混合专家模型 #小工蚁 #deepspeed
开源Mistral 7B开箱测试 性能炸裂,推理比Qwen-7B快4倍 #小工蚁
书生200亿开源大模型开箱测试 如何在2块GPU上运行? #小工蚁 #开源大模型
Huggingface开源新框架Candle让大模型运行在各种设备上 #小工蚁 #huggingface
如何提高垂直领域RAG准确率? #小工蚁
清华发布SmartMoE一种高效训练专家模型网络算法 #小工蚁 #清华 #MoE
大语言模型快速JSON解码算法 Jump Forward Decoding #小工蚁
TGI让Huggingface Transformer推理速度提升10倍,本地演示 #小工蚁 #huggingface
阿里发布Text2SQL最新实践开源模型准确度超GPT4
在RAG应用中LLM不同上下文检索和推理准确度不同 #小工蚁
演示ChatGLM-6B加载本地知识库精确回答财税问题
让Mixtral-8*7B模型运行在16GB显存GPU上 #小工蚁
开源FastLLM加速推理性能究竟如何?#小工蚁
使用Triton内核加速Llama3-70B FP8推理 #小工蚁
最强7B模型Zephyr,打败LlaMA2-70B #小工蚁
华为盘古Pangu-Code2:如何微调出接近GPT4水平的性能?
书生200亿开源大模型压力测试 算法优化后性能飙升几十倍 #小工蚁 #开源大模型