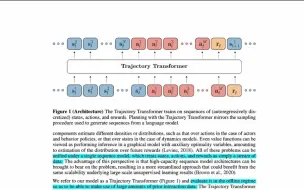
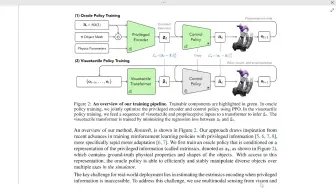
V
主页
京东 11.11 红包
多臂赌博机问题的求解 part1
发布人
简单介绍了多臂赌博机(multi-arm bandit)问题的设定,基础概念与初步的求解方式 part1
打开封面
下载高清视频
观看高清视频
视频下载器
【全874集】目前B站最全最细的ChatGPT零基础全套教程,2024最新版,包含所有干货!一天就能从小白到大神!少走99%的弯路!存下吧!很难找全的!
【论文代码复现122】基于强化学习的路径规划问题||强化学习和群智能优化算法有什么区别
代码实现大模型强化学习(PPO),看这个视频就够了。
【比刷剧还爽!】太完整了!中国科学院大学和上海交大强联合的(PyTorch+深度学习+强化学习+机器学习)课程分享!快速入门极简单——人工智能_AI_神经网络
从模型预测控制到强化学习12:DDPG做动态控制-研究生入学培训答疑
我愿称李宏毅强化学习为天花板课程!简单易懂!清晰明了的 PPO算法强化学习入门教程!深度强化学习、人工智能、神经网络
【MPC+强化学习】四大名校教授精讲强化学习和模型预测控制18讲!Actor Critic模型预测控制、策略梯度方法
【具身论文阅读】Diffuser: 基于diffusion的强化学习规划器
Decision transformer&Trajectory transformer 串讲以及未来方向思考
【全网疯传】比付费还强10倍的自学人工智能全套教程,全程通俗易懂,别再走弯路了,小白看完速通人工智能!机器学习|深度学习|计算机视觉|神经网络|人工智能
从模型预测控制到强化学习12:DDPG做动态控制-研究生入学培训答疑
【中英字幕】强化学习和模型预测控制18讲!四大名校教授精讲模型预测控制、最优控制、强化学习入门
【基于深度强化学习的冠军级别无人机竞速】强化学习和模型预测控制MPC中英字幕18讲!
不愧是李宏毅老师讲的【强化学习】简直太详细了!!小白也能信手拈来,学完可就业!-附资料(人工智能|机器学习|深度学习|强化学习)
这绝对是B站目前讲的最好的最完整【强化学习实战】教程!带你从零详解PPO算法/DQN算法/A3C算法教程!
双热点强强联合的发文方向:Transformer+强化学习!
Transformer+强化学习成为双热点强强联合的发文方向
【李宏毅】强化学习课程完整版千万不要错过!简单明了的PPO算法讲解!深度强化学习、人工智能、机器学习、大模型
【具身论文阅读】通用的视触觉的灵巧手操作
万字解析OpenAI o1(下)预期与问题
【SD整合包】Stablediffusion保姆级教程 SD教程零基础入门到精通 某叶大佬SD启动器 秋ye软件安装包 系统教程AIGC人工智能AI绘画教程全套
运用AI技术实现游戏自动化!所用到的YOLO技术原理原来是这样的!计算机大佬手把手教学YOLOv5基础原理及代码复现!
卧槽!这么好的【无人驾驶技术】全套教程不能只让我一个人学习,感知实战、视觉定位、路径规划、预测系统,翻遍全网找不到比这更详细的了!!!(自动驾驶/人工智能AI)
我愿称之为强化学习天花板课程!台大李宏毅教授亲授强化学习教程,究极通俗易懂!建议收藏!
【全网最细】逼自己一周吃透AI大模型(LLM+RAG系统+GPT-4o+OpenAI)通俗易懂,2024最新版,学完即就业!!
不愧是李宏毅老师讲的【强化学习】简直太详细了!!小白也能信手拈来,建议收藏!(人工智能|机器学习|深度学习|强化学习)
强化学习教父Sutton持续反向传播算法登Nature!证明深度学习还不如浅层网络
强化学习框架-Legged Gym 训练代码详解
大模型如何增强强化学习?简单粗暴理解大模型训练中的人类反馈强化学习RLHF!PPO算法、ChatGPT背后的数学原理
IsaacLab实现四足机器人AMP,视频训了1000轮,开源链接在简介
【网工】B站2024最新最全的华为认证网工全套HCIA+HCIP+HCIE喂饭级教程,带你从0基础到进阶!建议所有想入门网工的同学死磕这条视频,全程干货无废话!
一步步教AI玩游戏,强化学习通关教程!2024必学AI课程,赶紧收藏学习起来吧!
【强推】李宏毅深度强化学习完整版教程!简单易懂的PPO算法强化学习入门课程!近端策略优化、Transformer
终于看懂了神经网络、线性回归、梯度下降这些机器学习核心概念了!这个逐步可视化教程我能刷一天!
【即插即用】Pybullet端强化学习算法训练机械臂
强推!我敢保证这是B站最全的(python+机器学习+深度学习)系列教程,3小时就能从入门到精通,通俗易懂,小白也能学得会!人工智能|深度学习|计算机视觉
IsaacLab交流群及文档更新说明
【200集付费】一口气学完回归算法、聚类算法、决策树、随机森林、神经网络、贝叶斯算法、支持向量机、神经网络等十二大机器学习算法!
《强化学习》第4.1-4.3章 策略更新规则(上)
【大模型+强化学习】怎么理解大模型训练中的RLHF(人类反馈强化学习)?ChatGPT背后的数学原理