V
主页
2 Hadoop目标与生态系统
发布人
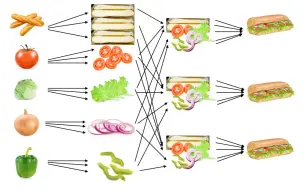
Hadoop分布式文件系统,或 HDFS,是许多大数据框架的基础,因为它提供可扩展且可靠的存储。一种分布式文件系统,可提供对应用程序数据的高吞吐量访问。 Hadoop YARN 作业调度和集群资源管理的框架。提供HDFS 存储上的灵活调度和资源管理。 YARN 用于雅虎调度40,000 台服务器上的作业。 MapReduce 是一种编程模型,用于并行处理大型数据集。简化了并行计算。不用处理复杂的同步和调度,只需要给MapReduce两个函数, map和reduce。这种编程模型非常强大,谷歌之前用它来索引网站。 MapReduce 只假设一个有限的模型来表达数据。 Hive 是创建Facebook的 ,用于在HDFS中对数据使用MapReduce发出类似sql的查询。 Pig 是 Yahoo 创建的,用于使用MapReduce对基于数据流的程序建模。 为了有效地处理大规模的图形,建立了Giraph。例如,Facebook使用Giraph来分析其用户的社交图谱。 同样,Storm、Spark、Flink 是在 YARN 资源调度器之上构建的对大数据进行内存处理的实时计算框架。 内存处理是一种强大的方法,更快地运行大数据应用程序,在某些任务上实现 100 倍的更好性能一些任务。 有时,您的数据或使用该文件不容易有效地表示处理任务。这方面的例子包括键值集合或大型稀疏表。 NoSQL 项目,例如 Cassandra,MongoDB 和 HBase 可以处理这些情况。 Cassandra 是在 Facebook 创建的,但 Facebook 也将 HBase 用于其消息传递平台。 最后,运行所有这些工具需要一个集中管理系统来进行同步、配置以确保高可用性。 Zookeeper 执行这些职责。它是由雅虎创建的以动物命名的服务。 Zookeeper:所有工具的集中管理系统,保证同步、配置和高可用性。
打开封面
下载高清视频
观看高清视频
视频下载器
美国儿童科普动画FreeSchool(中文配音版) - 第61集 生态系统
实验五 MapReduce编程案例实战 单词统计WordCount实践
3.7.2 硬间隔SVM数学求解与例题
【陆晨】《生态系统 Ecosystem》试玩
《生态系统》登陆Steam 创意进化冒险
休闲放置类古神生成器!!!【生态系统】
【生态系统】海 底 大 i m p a c t
市级优质教学比赛课——生态系统的信息传递
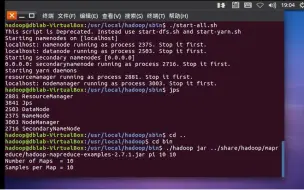
实验二 hdfs HDFS基本操作Shell命令实践( hadoop)
基于密度的聚类 DBSCAN 解释与实例计算
省级优质公开课——生态系统的能量流动
基于贝叶斯网络的生态系统服务驱动力及情景分区
4 HBase概述、体系结构与数据模型(HadoopPeople表为例)
决策树 ID3 计算实例
模拟上帝:两年半前我在家中打造了一个海马生态缸
耗时多少天?才能将一个空鱼缸打造成繁荣兴盛的生态系统?
生态系统理论:影响人生的5大力量 | 布朗芬布伦纳
关联规则挖掘FP-growth FPGrowth算法例题解析
种水草,主打一个和谐。【生态系统】
1 理解大数据的5V特征——Understanding the Vs of Big Data
鲑鱼,供养了整个生态系统!
信息熵与信息增益概念解释
【生态系统】甲壳激战!!!海底爬行!!!
3 HDFS hdfs目标、体系结构与特性
k-means kmeans聚类算法 清晰解释(带算例)
实验七 利用Eclipse编译运行MapReduce程序WordCount
实验八 MapReduce案例WordCount2.0扩充与Eclipse实现
实验一 熟悉Linux基本操作和hadoop圆周率计算实现 (与实验室同环境)
实验三 HBase Shell命令 创建HadoopPeople表
实验十六 hive网站用户行为分析 步骤二 hive数据分析
knn最近邻算法 带例子example
实验十五 hive网站用户行为分析 步骤一 本地数据上传到hive
实验六 MapReduce编程案例实战TopN
7.1 用纸牌游戏解释MapReduce编程模型与WordCount案例流程
用Python进行apriori关联规则挖掘实验
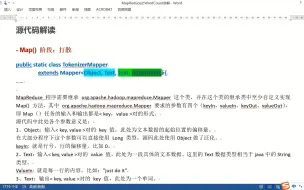
7.2 MapReduce实现WordCount源码解析
实验十一 spark RDD基本操作命令实践
实验十 spark submit shell操作命令WordCount实践
实验四 MongoDB Shell
遇事不决,苹果美学。沉浸式体验苹果的生态系统