V
主页
京东 11.11 红包
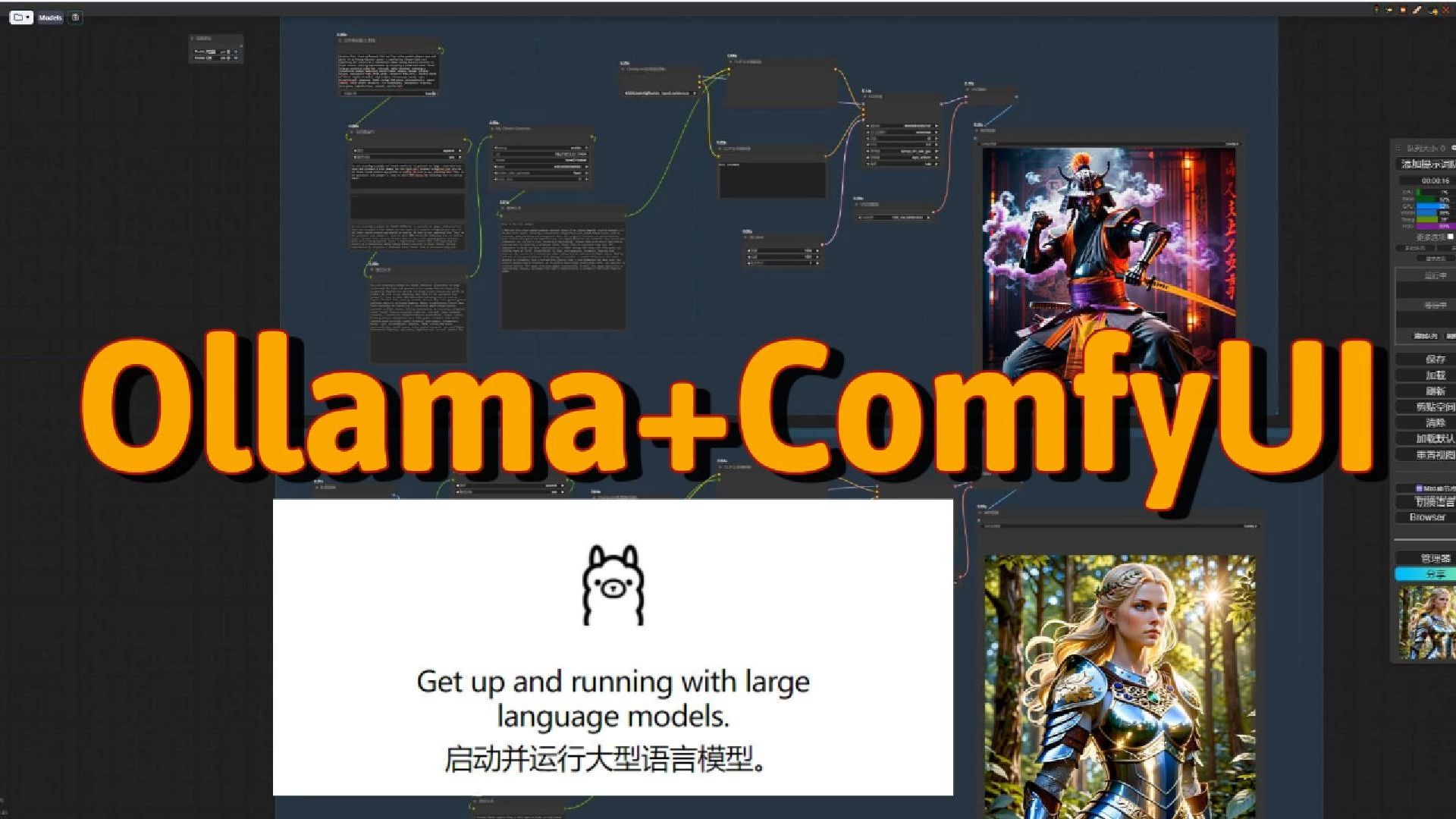
语言模型在ComfyUI中的应用,Llama 3.1生成提示词,LLaVA1.6图像反推
发布人
打开封面
下载高清视频
观看高清视频
视频下载器
Ollama提示+Flux.1生成图像,对Flux提示词生成的探索
图像反推打标必备,llava-v1.6-34b多模态语言模型助力,图像询问器
ComfyUI-OMost,大型语言模型驱动图像区域合成,充分提示词的理解
高分辨率AI长视频生成,超越SVD,EasyAnimate在ComfyUI中的实现
FLUX模型一致性角色的生成,无需借助外力
Segment Anything分割万物二代,准确性增强&6倍提速,支持图像和视频
Flux模型Hyper-SD加速+SD放大,更快的Flux图像放大
MimicMotion图片+骨骼动画生成视频,AnimateDiff Refiner细化,显存要求更低,效果提升
AuraFlow-6.8B完全开源的体积最大的文本到图像模型,评测
CogVideoX创建两张图像之间插值动画,使用Flux模型生成连续帧的网格图像
Animatediff-MagicTime模型,生成时间流逝效果的视频
对极其模糊的图片进行放大,想象力释放,SDXL-Tile应用
Flux模型的IP-Adapter风格迁移+ControlNet主体控制+Ollama自动提示+Hyper-SD加速
FLUX模型通用产品摄影,IC-Light光影统一,细节完全保留
FLUX区域提示词,分区域绘图工作流
Densediffusion区域控制的最终解决方案+Ollama语言模型,可控版Omost
Joy Caption反推提示词保姆式安装教程,如何解决所遇到的报错冲突问题以及环境配置 (附带Comfyui纯净整合包)
FLUX-NF4更新V2版本,精度更高,速度更快,FLUX-GGUF模型发布、对比
最好用的自然语言反推打标工具-Joy caption 2更新ComfyUI实现
FLUX改进的CLIP-L模型,更好的文本和提示遵循
MiniCPM多模态模型在ComfyUI中的实现,&LLaVA34B&Florence2的反推对比
UltraEdit提示词自动识别内容进行高质量重绘,基于SD3&LLM的图像编辑技术
ComfyUI中最好用的背景去除节点InSPyReNet,精准抠图至发丝
ComfyUI手部修复的新方法!ControlNet新预处理器和模型效率组合
ComfyUI-SuperPrompt提示词自动扩充模型,one button prompt组合应用
Llama3携手ComfyUI进行提示词驱动,灵感爆发!
SDXL-Tile模型更新,增加更多可玩性
服装Lora模型训练,流程记录
真实图像到动漫风格的转换,喵手结构化反推+图生图,学以致用,Flux工作流深度解析
创建惊艳的3D全景梦境,+语言模型解析梦境细节,ComfyUI-Dream-Interpreter
AnimateLCM,以最少的步骤生成高保真度的视频
没有损耗的将生成速度提升25%,ComfyUI-TensorRT
测评ComfyUI-IC Light控光节点,图像重打光、法线贴图生成,6个工作流解析
FLUX的IP-Adapter模型,XLabs更新,测评
使用 Llama-3.2的微调模型为Flux创建提示,Flux模型未蒸馏版本工作流汇总
AnimateDIFF Lighting,4步生成视频,更快~
Flux模型的手部重绘修复工作流,Florence2+局部细化+手部Lora
FLUX模型生成的最优参数调节,采样器、调度器、guidance等测试观点分享
Comfyui:IP-Adapter结合Open Pose+AnimateDiff生成可控动态视频,并进行高清修复
FLUX.1更新Canny模型,300种艺术风格分享