V
主页
1.3 梯度下降和随机梯度下降
发布人
打开封面
下载高清视频
观看高清视频
视频下载器
10.5 随机高斯策略
8.1 策略梯度中的基线
10.3 深入分析 DPG 10.4 双延时确定策略梯度 (TD3)
1.3.2 反向传播
7.1 策略网络 7.2 策略学习的目标函数 7.3 策略梯度定理的证明
3.4 价值函数 3.5策略学习和价值学习
6.1 经验回放与优先经验回放
18.2 蒙特卡洛树搜索(MCTS)
10.2 确定策略梯度 (DPG)
1.Latex创建参考文献
3.1 马尔可夫决策过程-基本概念
1.1 线性模型-最小二乘法回归
4.2 时间差分 (TD) 算法
1.1 线性模型-Softmax多分类问题
3.2 马尔可夫决策过程-随机性
2.2 蒙特卡洛(一)
12.3.2 12.3.3 GAIL 的训练
4.4 Q 学习算法 4.5 同策略 (On-policy) 与异策略 (Off-policy)
6.2 高估问题及解决方法
13.1 并行计算基础
1.1 线性模型-逻辑斯蒂二分类问题
Latex创建定理
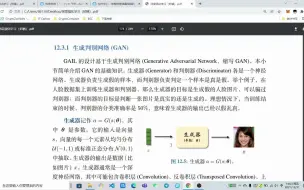
12.3.1 生成判别网络 (GAN)
Bot5-1
18.3 训练策略网络和价值网络
Bot1-2
怎么才能擅长 高效的解决棘手的问题
2.2 蒙特卡洛(二)
8.3 Advantage Actor-Critic (A2C)
2.1 概率论基础
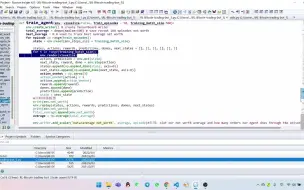
1.创建训练模型及训练算法
3.3 马尔可夫决策过程-回报与折扣回报
9.1 Trust Region Policy Optimization (TRPO)
什么?二分之一阶导数?i阶导数?(Riemann-Liouville分数阶导数)
【必看,信息量极大】高盛闭门会|中国出口增长将大幅下降,对经济增长贡献将下降至0.1%,内需成为增长决定性因素!
Bot3-5
3.6 比较和评价强化学习方法
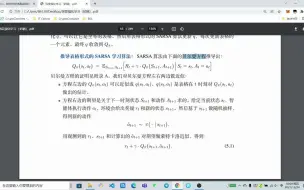
5.1 表格形式的 SARSA
9.2 熵正则 (Entropy Regularization)
13.3 并行强化学习