V
主页
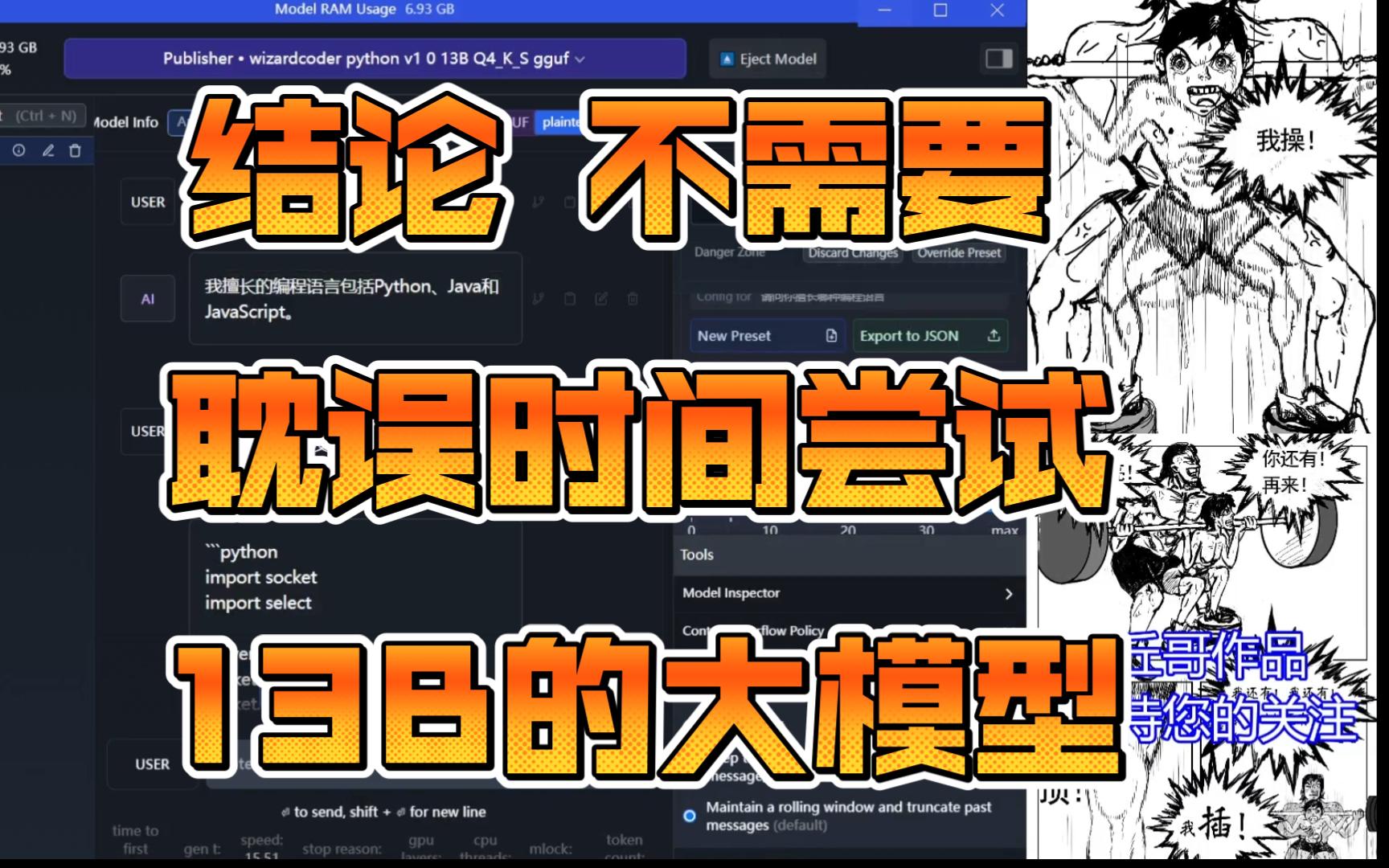
【13B大模型无用】大家不需要用自己的8G显存跑大模型了,没意义,70B也许成,我试试
发布人
【13B大模型无用】大家不需要用自己的8G显存跑大模型了,没意义,70B也许成,我试试
打开封面
下载高清视频
观看高清视频
视频下载器
半块RTX4090 玩转70B大语言模型
从0.5B到340B的LLM都需要多少显存?
本地语言模型个人推荐
推理能力最强的llama3.1 405B,不属于中国人
高质量翻译任何你想要的内容!AITranslator V2.0最新版!RPG游戏,SRT字幕,日文轻小说全流程汉化手把手教程!
核能挑战:8GB显存本地跑Llama 405B
22GB不够64GB怎么样?
苹果M2 Ultra:AI大模型的新希望
4090逆天的ai画图速度
我们训练了一个没有道德限制的大模型
5分钟学会微调大模型Qwen2
开源AI社区有多爱苹果电脑?
llama3 70B性能对抗测试,真的比肩GPT4了吗?开源社区王炸?开发这一模型的思路是什么?
千问Qwen2 7B模型8g显存运行效果,23Token/s
phi3 最强小模型 ollama本地测试
大语言模型虎扑评分,你最常用哪个?Chatgpt4!【虎扑锐评】
主流大模型哪个更适合日常使用,llama 3.1/Qwen2/GLM4大对比
大模型对比 | qwen:72b和llama3:70b
Qwen2很好,但我选GLM4
不要浪费钱买课了,喂饭式教你训练大模型llama3
大语言模型量化损失测试 fp16/int8/int4成绩对比
大模型现在已经可以逆向代码了,什么概念?
没有GPU也不愁,基于Groq API无压力使用Llama 3 8B & 70B 开源大模型
【一键包】谁也不能阻止我和AI小姐姐涩涩,显存不够内存来凑!|无限制|解除思想钢印|AI女友|教程|语言模型|人工智能
4060Ti 16G显卡运行百川2-13B大模型效果
【基德】AI即将演化为一场泡沫
最强垃圾王Tesla P40 24GB
小米14安装运行Qwen1.5-14B开源大语言模型(无需联网)
【ChatGLM】本地版ChatGPT?6G显存可用!ChatGLM-6B 清华开源模型一键包发布 可更新
高速翻译!无需等待!Sakura 1B8,Qwen 1B8以及Qwen1.5 14b 双语通用模型介绍
挑战Llama3!本地部署Gemma2开源模型!27b参数超越70b参数!ollama+Perplexica打造最强AI搜索引擎!#ollama #gemma2
为什么说14b是qwen2.5的更优解
万元CPU本地跑qwen2:72B大语言模型!
在4090上完美运行70B的llama2模型
调教出来一次不受伦理道德法律限制的独立ChatGPT,魅魔形态,可惜很快又被数据监管扼杀在摇篮里
qwen大模型地部署和微调法律大模型(只需5G内存)
M3 max 48g 跑Llama3 70b 4bit
Gemma2和Qwen2谁才是开源一哥?
本地运行通义千问72B!兼容AMD显卡或纯CPU【LM Studio】
Windows下中文微调Llama3,单卡8G显存只需5分钟,可接入GPT4All、Ollama实现CPU推理聊天,附一键训练脚本。