V
主页
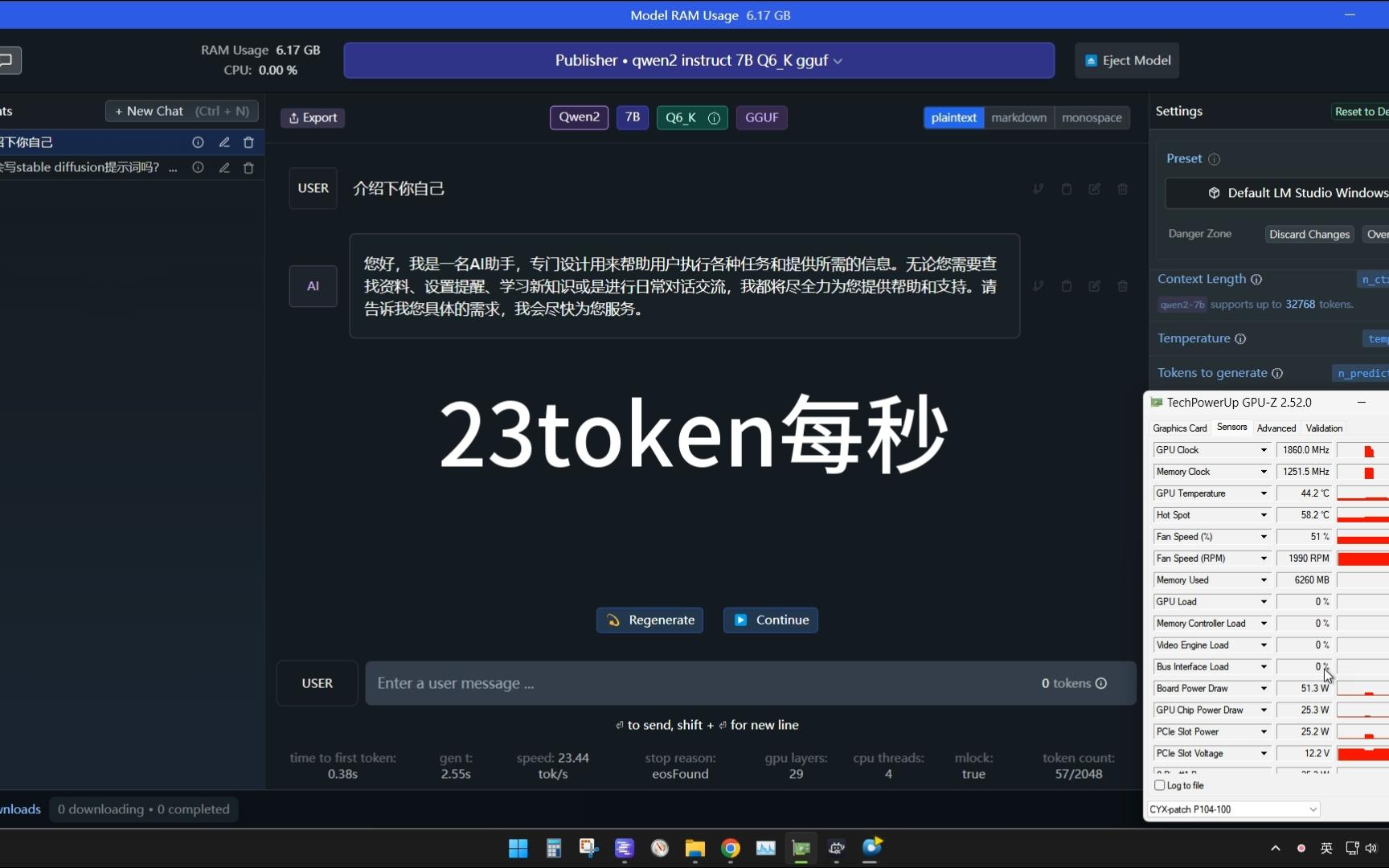
千问Qwen2 7B模型8g显存运行效果,23Token/s
发布人
打开封面
下载高清视频
观看高清视频
视频下载器
通义千问7B在RTX4080上推理运行实况
12GB版3060本地运行(Int8量化)Qwen2-VL-7B-Instruct 推理速度
在服务器上部署通意千问Qwen-7B开源大模型
200元显卡大战Qwen2.5-32B,垃圾佬也想跑本地大模型,P104双卡Linux下Ollama跑Local LLM
【Qwen2-VL】一键包 千问2视觉语言大模型开源 2B、7B以及72B
Qwen2为何“高分低能”?实测中表现还不如Qwen1.5!
Qwen2新模型,真的很能打吗?
Qwen2-Vl本地整合包,AI视频理解,AI图片理解,千问2视觉模型测试,基于视频的问答、对话、内容创作等方式理解20分钟以上的视频
英伟达4090实测通义千问Qwen-72B-Chat 模型性能
为什么说14b是qwen2.5的更优解
Qwen2很好,但我选GLM4
[测试] qwen 0.5b 1.8b 7b 14b 模型翻译文本测试 14b 效果不错 7b 可以接受
主流大模型哪个更适合日常使用,llama 3.1/Qwen2/GLM4大对比
核能挑战:8GB显存本地跑Llama 405B
qwen2 大语言模型发布了,具体如何本地安装部署,和 1100 亿参数 130G 大小的阿里千问1.5差距如何?
用最简单的方法本地运行新Qwen2大语言模型
Qwen2 72B Instruct 全量模型本地运行实测
【HomeLab】Qwen-72B 大模型 离线 私有 本地部署 演示
【13B大模型无用】大家不需要用自己的8G显存跑大模型了,没意义,70B也许成,我试试
沉浸体验4060Ti 16G显卡运行Qwen2.5大模型的效果
【大模型部署】Ollama部署Qwen2及llama.cpp补充
2024年6月7日千问2.0大模型开源发布!本地部署抢先体验!
清华智谱chatglm4-9b-chat和qwen2-7b-chat哪个更强?
手机安装运行最新开源的Qwen2-7B-Instruct大语言模型(可断网使用)
如何轻松部署Qwen2:本地与云端部署指南! Qwen2、Llama3、GPT4o,模型深度对比。
国产AI到底行不行?测试完通义千问,我只想说两个字【深度模评02】
Qwen2双语字幕自动化翻译,AI字幕翻译,千问2大模型,视频双语字幕翻译,翻译绅士内容,看懂老师们说什么
本地运行通义千问32B!不吃配置保护隐私,可兼容AMD显卡或纯CPU
最新Qwen2大模型环境配置+LoRA模型微调+模型部署详细教程!真实案例对比GLM4效果展示!
最便宜的48GB显存运算卡-RTX8000
国内安装使用LMStudio,本地AI必备神器。众多多新功能:API服务器,多模型,多模态之视觉识别……
阿里豁出去了!开源了通义千问全尺寸模型(本地部署Qwen2-VL教程)
通义千问7b开源魔搭社区!现场直播模型微调+部署
Qwen2本地部署和接入知识库 支持N卡/A卡/纯CPU
本地部署 通义千问 Qwen2 7B
千问2-1.5B大模型本地部署
用72B Qwen2跑一次GraphRAG要多少钱?
qwen大模型地部署和微调法律大模型(只需5G内存)
A卡/CPU运行大模型+知识库问答绝佳方案【AnythingLLM】
家庭PC本地部署LLama3 70B模型测试,对比70B和8B模型的效果,看看人工智障距离人工智能还有多远