V
主页
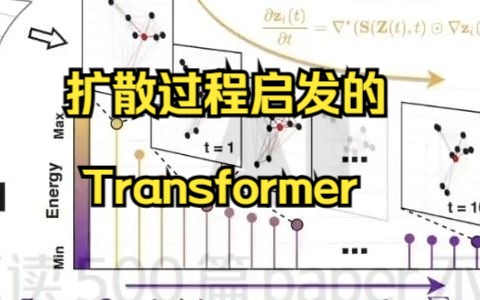
扩散过程启发的Transformer
发布人
【更多论文领取】 需要领取各论文方向的同学点击链接加我: 私发给你:https://dnu.xet.tech/s/Xq4b0
打开封面
下载高清视频
观看高清视频
视频下载器
【ICLR2023】扩散过程后发的Transformer:3GB显存实现,十万级样本间全联接的多层信息传递
CVPR2023必读的2篇Vision Transformer论文
即插即用,显著降低Transformer计算量的模型轻量化方法
训练时间降低70%,掩码Transformer扩散模型来了
【AAAI24】首篇方法论:统一各类GNN与扩散方程,扩散消息传递才是永远滴神!
ChatGPT-4 的31倍!Transformer的Token拓展至百万级
机器学习必读神书
【小样本合集】小样本学习必读的15篇顶会论文
讲Transformer自然语言处理的经典书
ResNet最新变体:性能反超Transformer,准确率达98.42%,19种改进方法一览无遗!
可解释模型预测登上Nature,热力学启发的解释性
Transformer+U-Net全新突破:荣登《Nature》,模型准确率暴涨至99.97%!最新14种创新手法
目前见过最全面的机器学习书,把概率机器学习讲透了
颠覆之作:MILA团队证明位置编码是多余的
想搞懂Transformer,一定不要错过的神书
目标检测综述,基于至今先进深度学习的目标检测模型综述
解释和改进安全应用中基于深度学习的异常检测
【ICCV2023回顾】一行代码即可见效,轻量注意力再升级!
深度学习计算机视觉代码可复现论文
液体神经网络:赶超Transformer!刷新SOTA!
基于RNN的长周期时间序列预测模型,优于SOTA Transformer效果【论文+代码】
【NeurIPS23】用于不规则时间序列的Transformer创新点剖析
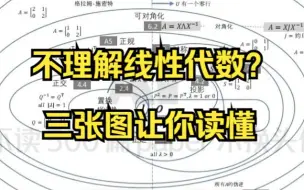
不理解线性代数?三张图让你读懂
无需看书、听课!学懂Transformer看这两篇博客就够了!
入门深度学习,怎样快速提升代码能力?
DeepMind发布升级版Attention
啊?MLP居然是很好的Transformer学习者? CVPR24最佳候选论文揭晓原因
如果把卷积网络设计变成一个数学问题,那会如何?【原文+代码】
transformer结合强化学习创新:组成端到端导航策略Agent,无需微调直接迁移!
结合创新:Patch+Transformer,计算成本狂降4倍!12种创新思路借鉴
24年图像生成创新潜力股:图像神经场结合扩散模型,任意分辨率就能渲染图像!
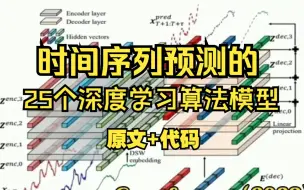
时间序列预测的25个深度学习算法模型【附原文+代码】
最新《时间序列预训练模型》综述
即插即用涨点种器:归一化层全新突破!
【中科院一区顶刊】即插即用的多尺度全局注意力机制
交互能力更强且具有语义感知的分割大模型
这是我迄今为止见过将 Chat GPT 原理最好的可视化。具象化的展示了Transformer神经网络模型结构。像在四维看三维。
阿里提出Mamba in Mamba!比现有SOTA提速10倍,相关学术24篇
扩散模型在医学图像上击败GAN
Transformer魔改策略又添一名新大将,循环门单元更新缓存,超越以往传统模型!