V
主页
京东 11.11 红包
Spark中有哪些机器学习库?
发布人
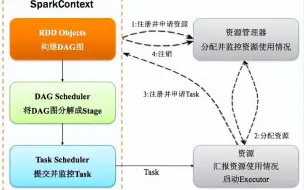
Apache Spark提供了一个名为MLlib(Machine Learning Library)的机器学习库,它是Spark生态系统的一部分。MLlib是一个强大的开源机器学习库,具有丰富的特性和工具,可以用于大规模的数据分析和机器学习任务。MLlib提供了多种常见的机器学习算法和工具,使开发人员能够在分布式Spark集群上进行大规模的机器学习。 MLlib包含了以下主要组件和功能: 1、分类(Classification):MLlib提供了各种分类算法,包括逻辑回归、随机森林、支持向量机(SVM)、朴素贝叶斯等,用于解决二元分类和多类别分类问题。 2、回归(Regression):MLlib支持回归问题,包括线性回归、决策树回归、梯度提升回归等。这些算法可用于预测连续性目标变量。 3、聚类(Clustering):MLlib提供了多种聚类算法,如K均值聚类、高斯混合模型聚类等,用于将数据分组成不同的簇。 4、降维(Dimensionality Reduction):MLlib支持降维技术,如主成分分析(PCA)和奇异值分解(SVD),用于减少数据维度,帮助发现数据的主要特征。 5、协同过滤(Collaborative Filtering):MLlib包括协同过滤算法,用于推荐系统和个性化推荐。 6、特征工程(Feature Engineering):MLlib提供了一系列特征处理工具,包括特征提取、特征选择、特征转换等,以帮助准备和优化数据集用于机器学习。 7、流式机器学习(Streaming Machine Learning):MLlib还支持流式机器学习,允许实时数据流上的模型训练和预测。 8、分布式学习:MLlib是基于Spark构建的,可以充分利用Spark的分布式计算能力,使机器学习任务可以在大规模集群上并行执行。 MLlib是Spark生态系统中的一个关键组件,它使开发人员能够在分布式环境中进行大规模数据处理和机器学习。除了MLlib之外,Spark还支持其他扩展机器学习库和框架,如TensorFlow、PyTorch等,允许用户根据具体需求选择适合的工具和库来开展机器学习任务。
打开封面
下载高清视频
观看高清视频
视频下载器
什么是Spark SQL?
什么是Spark GraphX?
Spark中的Shuffle是什么?
如何监控和调试Spark作业
如何将外部数据源与Spark集成?
Spark 和Hadoop MR 之间有什么区别?
什么是Apache Spark?
数据中台是怎么样的!面向数据治理与分析的大数据融合平台
大数据计算引擎 Spark
Spark的内存管理和调优机制
Spark Streaming 原理
Spark的数据处理模型是什么?
Spark 开源REST服务——Apache Livy(Spark客户端)
Spark中的数据缓存和数据持久化机制
Flink CDC 与 Debezium 有何关系?
【七天做完大数据毕设】基于Hadoop、Hive和Spark的当当网图书可视化分析系统 第8小节 可视化大屏
什么是ClickHouse?
数据湖与大数据?
【七天做完大数据毕设】基于Hadoop、Hive和Spark的当当网图书可视化分析系统 第7小节 可视化系统
k8s iptable 和 ipvs 模式的区别
什么是大数据
大数据 HDFS 工作原理
【七天做完大数据毕设】基于Hadoop、Hive和Spark的当当网图书可视化分析系统 第2小节 数据采集
什么是 etcd?
什么是数据湖?
什么是HBase?它与传统的关系型数据库有什么不同?
什么是 k8s DNS(CoreDNS)?
数据技术-第九期-再次聊聊数仓分层
Flink CDC 的实现原理是什么?
【大数据毕设】基于Hadoop/Spark商场数据分析系统可视化(Hive Spark Azkaban Springboot Vue)大数据项目计算机毕设
k8s 中 etcd 的作用?
ClickHouse是如何通过分析查询实现高性能的?
什么是 Elasticsearch?
【七天做完大数据毕设】基于Hadoop、Hive和Spark的当当网图书可视化分析系统 第3小节 数据存储
基于内存型SQL查询引擎 Presto(Trino)
为什么选择数据湖?
大数据 YARN 调度策略
大数据 YARN ProxyServer 服务
Prometheus TSDB 时序数据库工作原理?
如何自学嵌入式技术?