V
主页
Vision Transformer (ViT) 用于图片分类
发布人
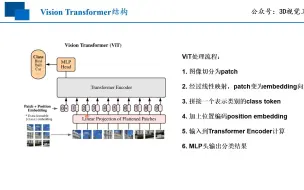
在所有的公开数据集上,Vision Transformer (ViT)的表现都超越了最好的ResNet,前提是要在足够大的数据集上预训练ViT。在越大的数据上做预训练,ViT的优势越明显。 课件:https://github.com/wangshusen/DeepLearning.git 参考文献: Dosovitskiy. An image is worth 16×16 words: transformers for image recognition at scale. In ICLR.
打开封面
下载高清视频
观看高清视频
视频下载器
11.1 Vision Transformer(vit)网络详解
11.2 使用pytorch搭建Vision Transformer(vit)模型
28、Vision Transformer(ViT)模型原理及PyTorch逐行实现
Transformer从零详细解读(可能是你见过最通俗易懂的讲解)
Transformer论文逐段精读【论文精读】
transformer实践(翻译、图片分类、目标检测、时间序列预测、图像分割)
VIT (Vision Transformer) 模型论文+代码(源码)从零详细解读,看不懂来打我
Vision Transformer的鸟类图像分类(200个类别)完整代码+数据
Vision Transformer--用Transformer做图像分类
VIT:用于大规模图像识别的Transformer,为什么会比CNN好?迪哥2小时带你吃透VITtransformer算法与代码!
彻底搞懂 Vision Transformer
Vision Transformer (ViT) 用于图片分类
关于Vision Transformer (ViT),你想知道的都在这里了!ViT近期进展整理
BERT (预训练Transformer模型)
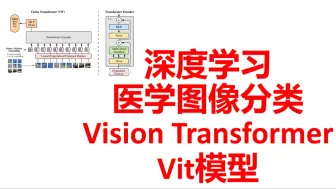
Vision Transformer (ViT)医学图像分类实战
ViT| Vision Transformer |理论 + 代码
Few-Shot Learning (1/3): 基本概念
VIT(vision transformer)模型介绍+pytorch代码炸裂解析
Vision Transformer打卡营
Swin Transformer论文精读【论文精读】
RNN模型与NLP应用(1/9):数据处理基础
【ViT模型】Transformer向视觉领域开疆拓土……
RNN模型与NLP应用(3/9):Simple RNN模型
Transformer模型(2/2): 从Attention层到Transformer网络
Transformer模型(1/2): 剥离RNN,保留Attention
ViT论文逐段精读【论文精读】
神经网络结构搜索 (2/3): RNN + RL Neural Architecture Search: RNN + RL
RNN模型与NLP应用(8/9):Attention (注意力机制)
如何搭建Transformer图像描述模型(Pytorch代码)
Vision Transformer(ViT)论文讲解(一)
RNN模型与NLP应用(9/9):Self-Attention (自注意力机制)
RNN模型与NLP应用(4/9):LSTM模型
[调包侠] 使用 PyTorch Swin Transformer 完成图像分类
绝对通俗易懂!4个小时带你啃透【SAM CLIP GLIP VIT四大模型】北大博士后卢菁博士授课-手把手教如何训练多模态大模型
Few-Shot Learning (2/3): Siamese Network (孪生网络)
什么是 ViT(Vision Transformer)?【知多少】
神经网络结构搜索 (1/3): 基本概念和随机搜索 Neural Architecture Search: Basics & Random Search
视觉Transformer是什么?ViT为什么是现在使用最广泛的模型?以及LLM的前世今生!
RNN模型与NLP应用(2/9):文本处理与词嵌入
相关性04:BERT模型 (Part 1) - 模型结构、线上推理