V
主页
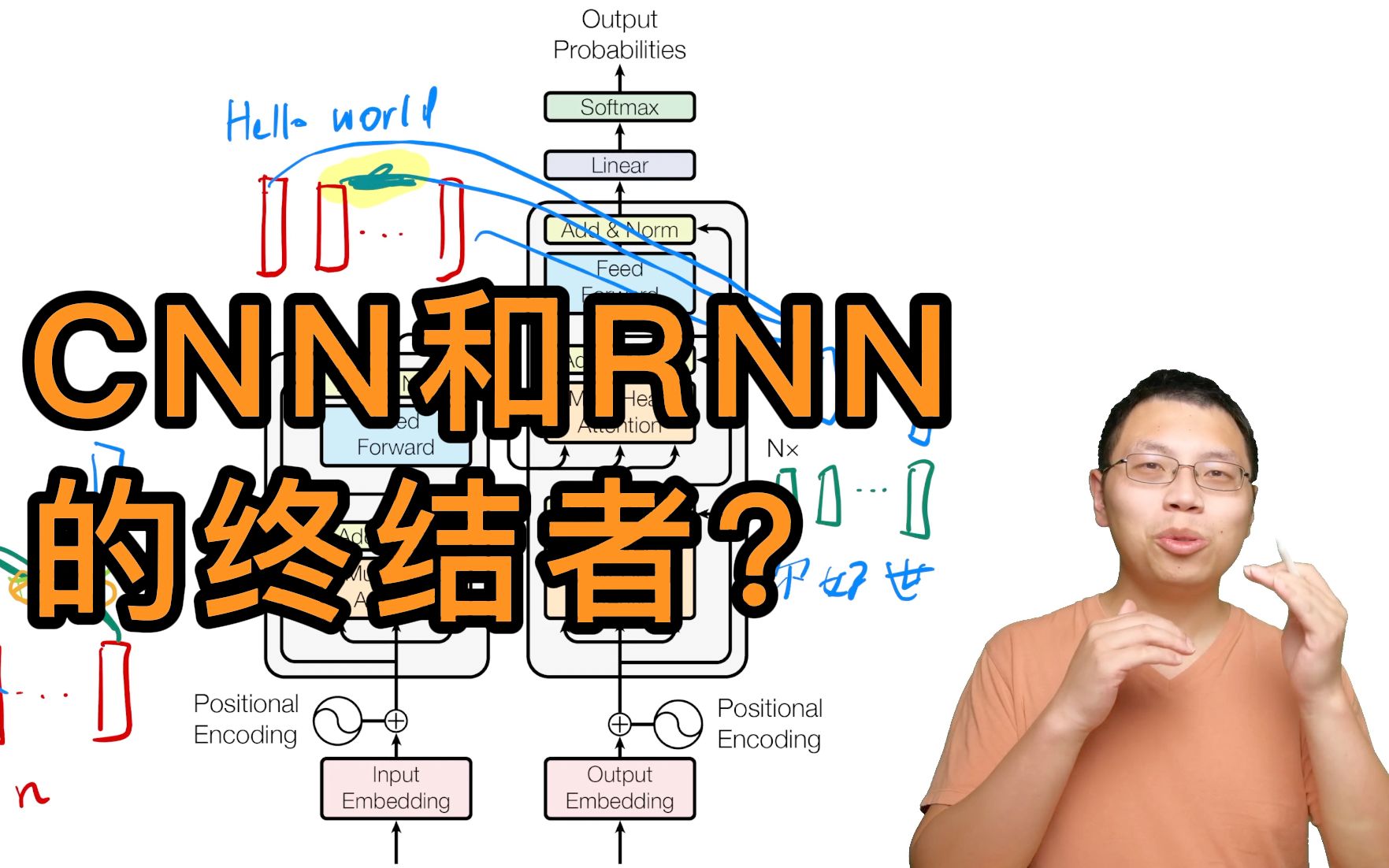
Transformer论文逐段精读【论文精读】
发布人
打开封面
下载高清视频
观看高清视频
视频下载器
19、Transformer模型Encoder原理精讲及其PyTorch逐行实现
GAN论文逐段精读【论文精读】
【研1基本功 (真的很简单)注意力机制】手写多头注意力机制
李沐-除非你是专家否则不建议搞图神经网络
Transformer和BERT看不懂来这里,告诉你他们的前世今生,必能懂
ViT论文逐段精读【论文精读】
ResNet论文逐段精读【论文精读】
09 Transformer 之什么是注意力机制(Attention)
Swin Transformer论文精读【论文精读】
李沐-打电话叫皮衣黄吃饭饭
CLIP 论文逐段精读【论文精读】
第1集 热血重燃!16名顶尖AI程序员助力科技反诈
如何读论文【论文精读·1】
BERT 论文逐段精读【论文精读】
【教材+源码】深度学习必看圣经!李沐大神《动手学习深度学习》最新版视频教程分享,比追剧还爽!(深度学习/神经网络/计算机视觉)
GPT,GPT-2,GPT-3 论文精读【论文精读】
MAE 论文逐段精读【论文精读】
【Transformer模型】曼妙动画轻松学,形象比喻贼好记
Transformer从零详细解读(可能是你见过最通俗易懂的讲解)
DETR 论文精读【论文精读】
【研1基本功 (真的很简单)Encoder Embedding】手写编码模块、构建Encoder Layer
手推transformer
Transformer 原理详解
【研1基本功 (真的很简单)Decoder Encoder】手写Decoder Layer 准备召唤Transformer
122集付费!CNN、RNN、GAN、GNN、DQN、Transformer、LSTM等八大深度学习神经网络一口气全部学完!
零基础多图详解图神经网络(GNN/GCN)【论文精读】
AlexNet论文逐段精读【论文精读】
对比学习论文综述【论文精读】
Transformer代码(源码Pytorch版本)从零解读(Pytorch版本)
参数服务器(Parameter Server)逐段精读【论文精读】
啥是大语言模型(LLM)?| AI大模型科普2
AlphaFold 2 论文精读【论文精读】
Attention机制(大白话系列)
热播剧《好事成双》,张小斐说LSTM比transformer效果好?
B站强推!2024公认最通俗易懂的【Transformer】教程,125集付费课程(附资料)神经网络_注意力机制_深度学习_BERT_大模型
【研1基本功 别人不教的,那就我来】SSH+Git+Gitee+Vscode 学会了就是代码管理大师
【梯度下降】3D可视化讲解通俗易懂
撑起计算机视觉半边天的ResNet【论文精读】
秒懂GPT✨是什么|动画讲解「Transformer」
如何做好文献阅读及笔记整理