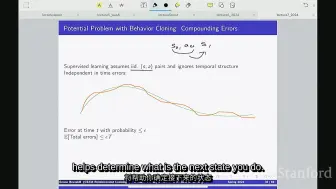
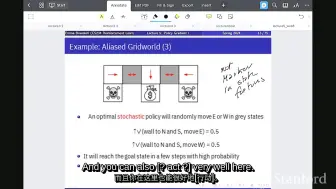
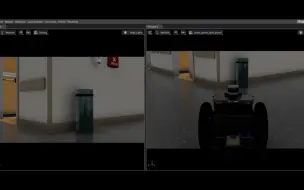
V
主页
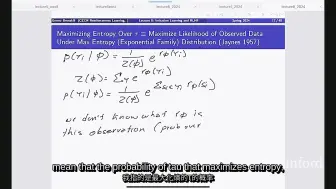
Lipschitz约束策略
发布人
项目地址: https://lipschitz-constrained-policy.github.io/
打开封面
下载高清视频
观看高清视频
视频下载器
SkillMimicGen:一个用于从少量人类示范中自动生成演示数据集的系统
LeRobot的大佬Alexander Soare讲解TD-MPC(1原理部分)
Andrej Karpathy大神的从头构建LLM系列-0
用于单、多机器人协助的学习框架
hil-serl训练全能机器人
你未来的家庭助手,真正的家务机器人
斯坦福大学2024强化学习-第7讲(策略梯度3)
郑秀晶-拉夫劳伦女孩的穿搭日常
人形机器人为什么需要腿,轮式不行么?
CoRL24-8 From Octo to π₀: How to Train Your Generalist Robot Policy
Atlas开始搬砖啦
马斯克为啥敢梭哈还能赢
使用ROS2-Control + RL来控制四足机器人
斯坦福大学2024强化学习-第5讲(策略搜索1)
分割一切fastsam模型,点哪里割哪里
使用docker运行SVO SLAM的老版本与新版本并成功运行
基于Isaac Sim虚拟环境的机器人自主探索
从谣言到“有图有真相”,我们该怎么对抗AI的深度伪造?
分割一切fastsam模型,助你成为抠图小能手
LeRobot的大佬Alexander Soare讲解TD-MPC(2操作细节部分)
CoRL24-10 Cross-Embodied Robot Learning with the Data Pyramid
Andrej Karpathy大神的从头构建LLM系列-2(MLP)
为什么Diffusion模型比自回归模型生成效果要好?
CoRL24-11 Discussion-Session: Cross-embodiment & the data pyramid
通向AGI之路
yolov8+fastsam实现实例分割与指定物体分割
CoRL24-7 Data Scaling Laws in Imitation Learning for Robotic Manipulation
Andrej Karpathy大神的从头构建LLM系列-4( Becoming a Backprop Ninja)
斯坦福大学2024强化学习-第8讲(离线学习1)
机器人看一下就学会
CoRL24-5 Im2Flow2Act
有这样的机器人男友,你晚上几点回家
Andrej Karpathy大神的从头构建LLM系列-1
斯坦福大学2024强化学习-第6讲(策略梯度2)
不愧是李宏毅老师讲的【强化学习】简直太详细了!全程干货,通俗易懂,看完就跑通!(人工智能|机器学习|深度学习|强化学习)
Arduino 车+机械臂 | Arduino Car with Robotic Arm
CoRL24-9 Avoiding a Robotics Winter by Beating Behavioural Cloning
什么是神经网络(这你也不想学呢)
斯坦福大学2024强化学习-第一讲(简介)
使用基础模型可验证地执行复杂的机器人指令