V
主页
京东 11.11 红包
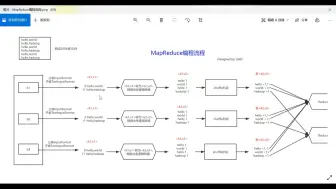
0078HDFS写数据流程2
发布人
0078HDFS写数据流程2
打开封面
下载高清视频
观看高清视频
视频下载器
097Spark基本架构01
085Spark核心功能01
092Spark核心功能08
093Spark核心功能09
098Spark基本架构02
086Spark核心功能02
0073HDFS副本存放策略1
094Spark应用模块01
002Hive简介02
003Flink前言
031Spark正式安装02
06Xshell连接虚拟机
002Flink课程介绍02
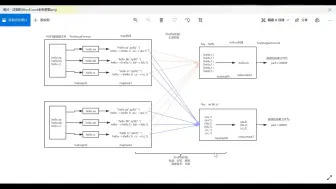
0094MapReduce核心思路4
095Spark应用模块02
0095MapReduce核心思路5
09JDK的安装
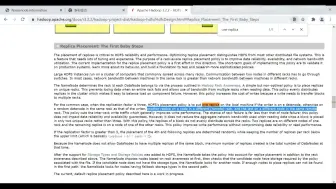
0090MapReduce优缺点
096Spark应用模块03
0098MapReduce核心思路8
0080HDFS相关题目讲解2
015大数据经典面试题-求最大的N个数02
003Hive简介03
0074HDFS读数据流程1
091Spark核心功能07
089Spark核心功能05
003Spark课程引言03
0015HDFS问题引入12预讲
12Hadoop启动之后页面访问
001Spark课程引言01
011MapReduce 执行引擎解析05
053Flink集群搭建06
0097MapReduce核心思路7
0068HDFS心跳机制1
02VMware软件的安装
0001大数据应用场景之物流
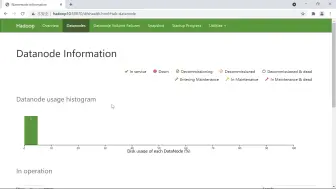
0034HDFS命令讲解1
099Spark基本架构04
04CentOS7安装过程中的一些必要性的设置
007Hive 和 RDBMS 的对比02