V
主页
京东 11.11 红包
003Flink前言
发布人
003Flink前言
打开封面
下载高清视频
观看高清视频
视频下载器
002Flink课程介绍02
001Flink课程介绍01
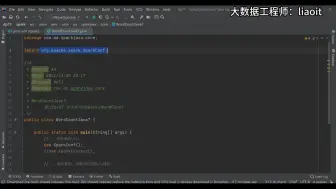
078Spark的Scala版本WordCount编写01
大数据求偶bfb
007MapReduce 执行引擎解析01
002Hive简介02
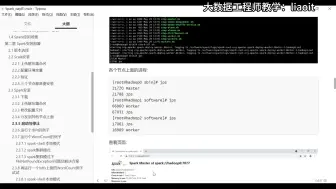
054Flink集群搭建07
【2024最新版】用Python处理Excel搞定自动化办公,几分钟轻松搞定一天工作,全天摸鱼(附带课件源码欧)
014大数据经典面试题-求最大的N个数
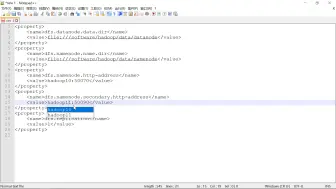
0039HDFS架构2
036Flink官网解读01
001Spark课程引言01
024Spark 执行引擎解析01
097Spark基本架构01
016MapReduce 框架核心流程01
059Spark的Java7版本WordCount编写01
006Hive 和 RDBMS 的对比01
096Spark应用模块03
0078HDFS写数据流程2
003Hive简介03
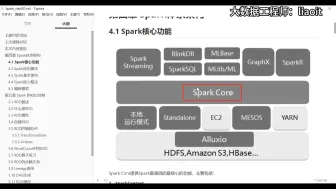
085Spark核心功能01
10Hadoop的安装
09JDK的安装
0092MapReduce核心思路2
032Spark正式安装03
060Spark的Java7版本WordCount编写02
009MapReduce 执行引擎解析03
084Spark体系架构前言
094Spark应用模块01
030Spark正式安装01
11Hadoop集群格式化与启动
009Hive架构02
076Spark的Java8 Lambda表达式版本WordCount编写04
086Spark核心功能02
092Spark核心功能08
089Spark核心功能05
详细解读:Flink指标体系
011MapReduce 执行引擎解析05
073Spark的Java8 Lambda表达式版本WordCount编写01