V
主页
[Generative AI进展,基于2D Label的3D感知的生成模型] CMU提出pix2pix3D,基于2D Label的3D感知的可控真实感图生成模型
发布人
3D-aware Conditional Image Synthesis Kangle Deng, Gengshan Yang, Deva Ramanan, Jun-Yan Zhu (CMU) 项目主页: https://www.cs.cmu.edu/~pix2pix3D/ Github主页:https://github.com/dunbar12138/pix2pix3D We propose a 3D-aware conditional generative model for controllable photorealistic image synthesis. Given a 2D label map, such as a segmentation or edge map, our model synthesizes a photo from different viewpoints. Existing approaches fail to either synthesize images based on a conditional input or suffer from noticeable viewpoint inconsistency. Moreover, many of them lack explicit user control of 3D geometry. To tackle the aforementioned challenges, we integrate 3D representations with conditional generative modeling, i.e., enabling controllable high-resolution 3D-aware rendering by conditioning on user inputs. Our model learns to assign a semantic label to every 3D point in addition to color and density, which enables us to render the image and pixel-aligned label map simultaneously. By interactive editing of label maps projected onto user-specified viewpoints, our system can be used as a tool for 3D editing of generated content. Finally, we show that such 3D representations can be learned from widely-available monocular images and label map pairs.
打开封面
下载高清视频
观看高清视频
视频下载器
[NeRF进展,街景重建方向] 复旦大学提出S-NeRF,将街景重建PSNR提升45%,可以兼顾大规模场景背景与前景移动车辆处理
现在的 AI 技术太强了,尔康:太为难我了
[NeRF进展,风格化与重着色,NPR方向]东京大学使用一种新的Palette提取方法,使NeRF重着色可达到实时性能,实现NPR效果(EGSR 2022)
[文本转3D,群友工作] 南京大学提出AvatarBooth,新的文本或图片生成高质量3D Avatar的框架,拍摄的脸或身体照片即可生成,可支持二次编辑
[NeRF进展,实时动态、静态6-DoF视频渲染]CMU, Meta等联合推出HyperReel,在低内存消耗下,实现实时的、高质量的、高分辨率的体渲染方法
[NeRF进展,鲁棒的动态NeRF]Meta,台湾大学、KAIST、马里兰大学提出RoDynRF,联合预测静态、动态和相机姿态焦点信息提升鲁棒性
[NeRF进展,人脸动画,褶皱渲染] 华沙工业大学、UBC、微软、Google等提出BlendFields,在少量数据下,结合图形学方法,生成细节表情动画
研究生宝藏公开课《神经网络与自然语言处理NLP》,号称AI第一重镇的CMU卡内基梅隆大学课程,分分钟带你上名校!!!(计算机专业/人工智能课程)
[Neural Rendering]Facebook Reality Lab提出AutoAvatar,推进神经场技术到真实人体动效生成领域(ECCV 2022)
[NeRF进展,雾状鬼影消除] 伯克利提出NeRFBusters,使用3D Diffusion模型,对随意捕捉的NeRF去除雾状鬼影
SyncTalk第五讲以deepspeech方式训练解决双下巴问题并新增NPY文件生成工具
[NeRF进展,稀疏输入视角重建]CMU提出GBT,在稀疏图片输入的情况下,使用几何biased Transformer显著提升稀疏图片重建效果
[NeRF进展,使用不同场景时期图片重建NeRF] 华盛顿大学、Google Research提出PersonNeRF,灵活使用各场景、时期图片重建人物NeRF
SyncTalk三种训练方式ave、deepspeech、hubert效果对比其中hubert防抖效果最好
[NeRF进展,3D形状表达] KAUST和TUM发表3DShape2VecNet,面向扩散生成模型的形状神经场表达,对3D形状编码和生成及多个下游任务非常有效
【AI视频音效生成】当AI遇见逮虾户,开源免费的AI工具为视频增添生动音效!
[Diffusion生成点云,开源]OpenAI开源大招Point-E,通过文本生成3D point cloud的方法,快速有效地生成多样化复杂的3D模型
[Diffusion+SDF,三维重建] 港中文、上海AI实验室、浙大提出DiffRoom,基于occupancy先验重建TSDF,生成高质量3D室内重建效果
[NeRF进展,复杂场景编辑]斯坦福大学、Adobe提出PaletteNeRF,对复杂场景的外观属性进行后期编辑,NeRF向Adobe产品家族整合成为可能
I3D 2023 Papers Session 1 - Neural Rendering and Image Warping
[NeRF进展,严重相机pose错位重建,强于BARF] 西安交通大学、蚂蚁金服、腾讯AI Lab提出L2G-NeRF,使用局部-全局优化相机严重错位重建问题
[3DGS几何优化]上科大、图宾根大学提出2DGS,一种从多视图图像中建模和重建几何精确辐射场的新方法,解决3DGS几何一致性差的问题
[NeRF进展]:LaTeRF,使用弱标记从图片中获得真实感3D物体表达(ECCV 2022)
[3DGS] 作者Bernhard Kerbl讲讲3DGS的历史、思考过程(感谢群友的投喂)
[NVS和三维生成进展] 香港大学、腾讯等提出SyncDreamer,不使用SDS损失,使用单图生成多视角一致性图片,进而使用Neus和NeRF重建三维模型
[NeRF进展,模型任意转换]北航、旷视提出PVD,可以实现任意到任意的模型转化,训练一个NeRF,可以使用框架进行处理(AAAI 2023)
[神经材质压缩] nVidia杀疯了,提出NTC,使用神经压缩算法压缩纹理压缩,在增加了两层LOD后,不需要熵编码的情况下低码率压缩,解码只增加毫秒级消耗
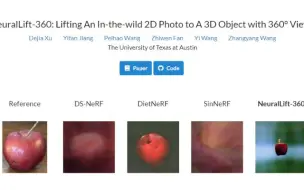
[NeRF进展,单图片成3D内容] 德克萨斯大学奥斯丁分校提出NeuralLift-360,使用单图生成3D物体
[Transformer进展,文本生成图片]GoogleAI提出Muse,首次使用Transformer代替Diffusion模型完成文本生成图片,速度快
纯文字生成AI视频,Stable Diffusion保姆级教程,1分钟快速教你掌握AI制作视频,AI绘画小白零基础入门到精通(附SD安装包及插件)
[NeRF进展,2D图片生成3D人体] 南洋理工大学提出EVA3D,通过使用人体的分解NeRF表达,使用2D图片集训练生成高质量3D人体模型
[NeRF进展,稀疏视角重建] 斯坦福,Google, SFU提出SCADE,使用cIMLE和space carving方法,提升稀疏无约束室内NeRF重建效果
[NeRF进展,文本生成NeRF场景] 香港城市大学、腾讯提出Text2NeRF,一种由文本生成NeRF场景的方法,室内外生成效果都不错
Runway可灵效果对比|Gen-3预定AI视频王座?我看未必……
[AIGC产品]Yi Shen即将发布一个新AI产品,2D图片转气球或乐高风格3D Mesh,支持导出,适合制作乐高,或者3D资产
[NeRF进展,鲁棒的动态NeRF] RoDynRF CVPR最终presentation视频,联合预测静态、动态和相机姿态焦点信息,提升动态nerf鲁棒性
[NeRF进展,大型城市场景建模] 香港中文大学、浙江大学、马克斯普朗克等发布GridNeRF,高效建模大规模真实感城市3D场景
[NeRF进展,动画方向] 东京大学在同年提出与我国CageNeRF类似的NeRF动画控制方法,同步了解别人的想法(ECCV 2022)
[Transformer进展,用人体动作合成场景,可结合文本合成3D继续生成新效果?]斯坦福、丰田研究院提出SUMMON,使用人体动作反向生成合理有效的场景
[神经网络驱动3D建模] 特拉维夫大学、芝加哥大学、普渡大学提出GeoCode,一个人类可解释、可修改编辑的3D建模方法,提升对生成模型的操控力