V
主页
[文本转3D,群友工作] 南京大学提出AvatarBooth,新的文本或图片生成高质量3D Avatar的框架,拍摄的脸或身体照片即可生成,可支持二次编辑
发布人
AvatarBooth: High-Quality and Customizable 3D Human Avatar Generation Yifei Zeng, Yuanxun Lu, Xinya Ji, Yao Yao, Hao Zhu, Xun Cao 项目主页:https://zeng-yifei.github.io/avatarbooth_page/ We introduce AvatarBooth, a novel method for generating high-quality 3D avatars using text prompts or specific images. Unlike previous approaches that can only synthesize avatars based on simple text descriptions, our method enables the creation of personalized avatars from casually captured face or body images, while still supporting text-based model generation and editing. Our key contribution is the precise avatar generation control by using dual fine-tuned diffusion models separately for the human face and body. This enables us to capture intricate details of facial appearance, clothing, and accessories, resulting in highly realistic avatar generations. Furthermore, we introduce pose-consistent constraint to the optimization process to enhance the multi-view consistency of synthesized head images from the diffusion model and thus eliminate interference from uncontrolled human poses. In addition, we present a multi-resolution rendering strategy that facilitates coarse-to-fine supervision of 3D avatar generation, thereby enhancing the performance of the proposed system. The resulting avatar model can be further edited using additional text descriptions and driven by motion sequences. Experiments show that AvatarBooth outperforms previous text-to-3D methods in terms of rendering and geometric quality from either text prompts or specific images. Please check our project website at [this https URL](https://zeng-yifei.github.io/avatarbooth_page/).
打开封面
下载高清视频
观看高清视频
视频下载器
[NeRF进展,雾状鬼影消除] 伯克利提出NeRFBusters,使用3D Diffusion模型,对随意捕捉的NeRF去除雾状鬼影
[Diffusion生成NeRF] TUM, Apple提出HyperDiffusion,用Diffusion计算神经场权重,统一框架下生成3D权重或4D动画
[Diffusion+NeRF进展]慕尼黑工业大学、Meta研究院提出DiffRF (也许是首次)基于扩散模型的3D辐射场生成方法
[单图生成3D] UCSD, UCLA, 浙大, 康奈尔等:One-2-3-45,Zero123+SDF,超快速生成3D且几何一致性高,图片或文本生成高质量3D
[NeRF进展,时变3D模型] 浙大,康奈尔,特拉维夫提出neusc,使用网上地标照片,重建可独立控制视点、光照和时间的真实感时变三维模型
[Diffusion+SDF,三维重建] 港中文、上海AI实验室、浙大提出DiffRoom,基于occupancy先验重建TSDF,生成高质量3D室内重建效果
[NeRF进展,效果提升] TUM与Meta推出GANeRF,使用GAN来解决视角观察缺陷以及小的光照变化带来的重建质量不佳问题,提升1.4dB以上
[NeRF+Diffusion进展,单图重建3D] 韩国首尔大学提出DITTO-NeRF,使用文字或单图,通过前视角部分3D+迭代扩散填充,生成3D模型
[NeRF+自动驾驶] 浙大、图宾根大学提出PanopticNeRF360,将3D标记与带噪声的2D语义线索组合生成一致性全景标签和高质量任意视角图片的方法
ECCV'24 7篇工作|3D大场景生成、视频问答自动评估、手写文本生成、虚拟试穿等
[NVS和三维生成进展] 香港大学、腾讯等提出SyncDreamer,不使用SDS损失,使用单图生成多视角一致性图片,进而使用Neus和NeRF重建三维模型
[神经材质压缩] nVidia杀疯了,提出NTC,使用神经压缩算法压缩纹理压缩,在增加了两层LOD后,不需要熵编码的情况下低码率压缩,解码只增加毫秒级消耗
[NeRF进展,2D图片生成3D人体] 南洋理工大学提出EVA3D,通过使用人体的分解NeRF表达,使用2D图片集训练生成高质量3D人体模型
[3D生成] 南洋理工、香港中文、上海AI实验室提出DiffTF,一个基于扩散模型和三平面的前馈框架,用于生成多样化的、大语料量规模的真实世界3D物体
[Diffusion进展] Google Research Imagen模型,提出一种新的图片生成文字的AIGC框架,更好的生成效果(NeurIPS 2022)
[NeRF纹理生成,SIGGRAPH] 中科院,腾讯等提出NeRF-Texture,从多视角图像采集和生成纹理,可应对如草、叶子、纺织品等3D空间复杂纹理生成
[群友SIGGRAPH工作] 上科大等推出DressCode,使用文本生成真实感服装,通过大语言模型交互生成CG友好的服装
[NeRF+Diffusion进展,少量输入重建] CMU提出SparseFusion,在最少两个输入视角情况下,可以完成3D一致性高的高质量重建
[NeRF进展,文本生成3D] Google,Ben、Jonathan提出DreamBooth3D,DreamBooth+DreamFusion,文本生成3D
[AIGC进展,使用shape+文本生成纹理] 特拉维夫大学提出TEXTure,通在已知3D shape情况下,使用文本可生成、编辑和迁移纹理效果
大规模3D场景生成全新工作!LT3SD:扩散模型杀疯了!
[NeRF进展,文本生成NeRF场景] 香港城市大学、腾讯提出Text2NeRF,一种由文本生成NeRF场景的方法,室内外生成效果都不错
[NeRF Relighting进展,SIGGRAPH] 浙大、微软亚研院等提出从一组物体的无结构图片,使用阴影和高光hints进行NeRF重光照的模型
[NeRF,场景语义建模与应用]Meta提出SSDNeRF,首个通用NeRF场景语义分割方法,将场景按语议分割建模,让NeRF二次编辑、丰富动画场景变为可能
[NeRF进展,Avatar实时生成] 苏黎世I联邦理工,普朗克研究所提出InstantAvatar,相比SOTA方法速度提升130倍以上,秒级别训练,实时渲染
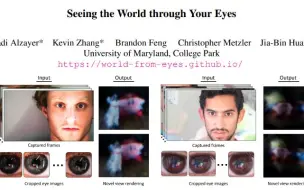
[NeRF进展,反射场景提取] 马里兰大学的新脑洞,通过眼睛反射重建所看到的场景,又一个使用神经场通过反射完成场景重建
[NeRF进展,单目视频重建动态人-物-场景] 新加坡国立大学,腾讯等提出HOSNeRF,使用单目视频动态人-物-场景,LPIPS相比SOTA提升40%以上
[NeRF进展] MPI提出NeuralClothSim,一种使用Kirchhoff-Love布料模拟方法,将表面变化过程编码到神经网络中,实现更好的模拟效果
[NeRF+Diffusion进展,少量视触目] Nitantic推出DIffusioNeRF,使用RGBD贴片训练的DDM模型,正则化few-shot重建过程
[NeRF进展,深度估计方向,群友推荐] 博洛尼亚大学、Google等提出NeRF监督的深度立体方法,使用NeRF监督更加准确的深度度和视差图,提升超过30%
[NeRF进展,单图片生成多视角] Apple, UC圣迭戈分校,马普所,宾大发布NerfDiff,使用CDM+NeRF提高生成质量与效果
[Diffusion进展,文本转视频]新加坡国立大学、腾讯ARC实验室提出Tune-A-Video,使用文本生成图片模型One-Shot精调至视频,效果很棒
[NeRF,三维风格化效果] NeRF-Art是由香港城市大学、香港理工大学、Snapchat、USC、微软等联合推出的文本驱动生成的NeRF风格化方法
[AIGC视频生生]Google等提出Lumiere,使用时空U-Net,单次传递,一次性生成视频完整时间,实现高质量文本转视频、图像转视频、视频修复、风格化等
[NeRF进展,城市建模] 南洋理工大学:CityDreamer,一种unbounded 3D城市设计的组合生成模型,效果超过SceneDreamer
[NeRF进展,开源大规模场景] DNMP(同济、港中文、上海AI实验室,CPII),一种使用可变形神经mesh的,高质量快速的重建和渲染城市级别神经场的方法
[NeRF进展,文本编辑NeRF] 创始大神Matthew+18岁大学生一作提出Instruct-NeRF2NeRF,使用文本指令进行3D场景的真实感编辑
[NeRF进展,语义驱动编辑] 浙江大学3DV国家重点实验室联合Google提出SINE,通过语义驱动NeRF编辑,完成多视角高质量、一致性的编辑操作
[Generative AI进展,基于2D Label的3D感知的生成模型] CMU提出pix2pix3D,基于2D Label的3D感知的可控真实感图生成模型
[NeRF进展,场景天气风格化渲染]UIUC、浙江大学,马里兰大学提出ClimateNeRF,在NeRF场景中融合天气物理渲染,实现真实感天气场景渲染效果