V
主页
20220713【超级视觉深度学习模型与标签学习方法】张敬:ViTAE Transformer 超级视觉深度学习模型
发布人
报告嘉宾:张敬 (The University of Sydney) 报告时间:2022年07月13日 (星期三)晚上20:00 (北京时间) 报告题目:ViTAE Transformer 超级视觉深度学习模型 报告人简介: 张敬博士,毕业于中国科学技术大学自动化系,现任悉尼大学计算机系博士后研究员,主要从事计算机视觉和深度学习领域的研究工作。目前已经在CVPR, ICCV, NeurIPS, ICLR, AAAI, IJCAI, ACM Multimedia, IJCV, IEEE T-IP, T-NNLS等会议和期刊发表论文50余篇。担任包括CVPR, ICCV, ECCV, NeurIPS, ICLR, ACM Multimedia, IJCV, IEEE T-IP等会议和期刊的审稿人,以及AAAI和IJCAI会议的高级程序委员会委员。 个人主页: https://scholar.google.com/citations?user=9jH5v74AAAAJ 报告摘要: 研究社区已经认识到大数据中蕴含着海量的知识,如何有效获取和利用这些知识是实现更强人工智能的关键。近年来提出的一种新型神经网络架构——Transformer,因其具有的很强的模型表征能力和可扩展性,使得更大的模型往往能更好地从数据中提取和利用知识,并取得更好的性能。本次报告将以我们在Transformer领域的最新工作ViTAE为例,从多个维度展示Vision Transformer“繁而不同“的特点,包括:更多的参数、更多的有标签和无标签数据、更多的先验知识、计算资源、视觉任务以及数据模态。特别的,ViTAE支持扩展到更大规模参数量的模型,支持更多的输入数据模态;ViTAE可以从更多的数据中提取和编码知识;ViTAE能以归纳偏置和约束的方式使用更多的先验知识;ViTAE还可以很简单地适配大规模并行计算资源从而实现更快的训练。ViTAE可以应用于多个计算机视觉任务并取得了显著进展,包括图像识别、物体检测、语义分割、图像抠图、姿态估计、场景文字理解和遥感影响分析等。相关代码和模型已经公开到 https://github.com/ViTAE-Transformer。
打开封面
下载高清视频
观看高清视频
视频下载器
20220713【超级视觉深度学习模型与标签学习方法】刘同亮:标签学习简介——助力超级深度学习
20220713【超级视觉深度学习模型与标签学习方法】Panel
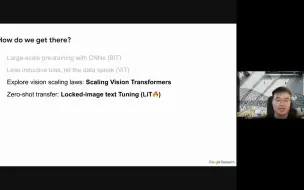
20220602智源大会视觉模型论坛-谷歌大脑翟晓华博士报告【大规模通用视觉表征学习】
20230531【大模型时代下的三维视觉:路在何方?】杨波:3D Semantic and Instance Segmentation without 3D……
20220615【AI for Science之物理信息驱动的深度学习】陆路:Learning operators using deep neural……
20220831【就正有道:物理机理驱动的图像恢复与增强】任文琦:融合先验知识的图像视频复原方法研究
20220309【让机器看懂视频:视频分割与目标追踪】杨宗鑫:视频理解中的多目标联合分割
20220529 VALSE Student Webinar【When CV meets NLP】都一凡:视觉-语言预训练模型综述
20210714【弱监督视觉学习:定位、分割及其他】万方:Weakly Supervised Object Localization:From CNN to…
【VALSE2024】0505 谢凌曦《APR:视觉通用人工智能》
20211222【自动驾驶中的机器视觉与学习问题】Panel
【2024最新完整版】不愧是李宏毅教授!一口气学完机器学习、深度学习、强化学习、NLP、生成式AI等课程!一套全解决!
20211124【标记高效的视觉学习】董力:BEiT: BERT Pre-Training of Image Transformers
20220323【我要找到你:2D/3D物体检测和定位】陈挺:Pix2seq: A Language Modeling Framework for……
20230531【大模型时代下的三维视觉:路在何方?】刘子纬:大模型时代下的3D AIGC
20240911【医疗人工智能的前沿进展】潘永生:跨模态影像生成技术发展与应用
20230106【铂金赞助商Webinar:华为】谢凌曦:华为云盘古视觉基础模型的挑战难题发布
20210331【物体检测与视觉定位】李文:领域自适应的目标检测
20220330特邀报告【数据驱动的强化学习及其工业应用】俞扬 (南京大学)
20220629【比物连类:对比表示学习】苏冰:What to contrast?
20211021【Transformer在医学图像处理的应用】付华柱:Transformers 在多模态 MR 成像中的应用
20240605【Prompt Learning in Vision】陈广义:Prompt Learning Meets Dense Context for …
20240911【医疗人工智能的前沿进展】马骏:Towards Biomedical Image Segmentation Foundation Models
20220629【比物连类:对比表示学习】Panel
20220316【基于领域知识的机器学习在医学影像分析中的应用】崔智铭:Shape-aware tooth segmentation in digital……
20230322【大规模预训练模型的可信性】Panel
20220420【点云场景理解】弋力:面向交互的四维动态场景理解
20240911【医疗人工智能的前沿进展】谷林:Bridging the Gap Between Medical AI Research and ……
20240731【多模态研究进展】徐偲:面向低质多模态数据的深度学习
20231206【三维大模型探索】欧阳万里:迈向三维视觉大模型
【VALSE论文速览-75期】联合分布很重要:深度布朗距离协方差用于少样本识别
【VALSE2024】0505 吴小俊《特邀报告:多模态视觉融合方法:是否存在性能极限?》
20220323【我要找到你:2D/3D物体检测和定位】Panel
20220803【妙笔生花,画龙点睛: 视觉生成式模型专题研讨】Panel
20210922 特邀报告【具身智能 (Embodied AI)】卢策吾 (上海交通大学)
20230322【大规模预训练模型的可信性】Chaowei Xiao:Towards Socially Responsible machine learning
20230329【多模态预训练的研究进展与未来】宋睿华:多模态预训练模型及在智能创作领域的应用
这才是科研该学!2024公认最通俗易懂的【深度学习】教程,从入门到精通一口气学完CNN、RNN、GAN、GNN、DQN、Transformer、LSTM
20220914【视频理解研究进展与未来】Panel
【课件+代码】李沐大神《动手学深度学习》2024最新视频教程,比啃书高效!比刷剧还爽!(人工智能丨深度学习丨神经网络)